h
Among the variety of penetration testing engagements NCC Group delivers, some – often within the gaming industry – require performing the assignment in a blackbox fashion against an obfuscated binary, and the client’s priorities revolve more around evaluating the strength of their obfuscation against content protection violations, rather than exercising the application’s security boundaries.
The following post aims at providing insight into the tools and methods used to conduct those engagements using real-world examples. While this approach allows for describing techniques employed by actual protections, only a subset of the material can be explicitly listed here (see disclaimer for more information).
Unpacking Phase
When first attempting to analyze a hostile binary, the first step is generally to unpack the actual contents of its sections from runtime memory. The standard way to proceed consists of letting the executable run until the unpacking stub has finished deobfuscating, decompressing and/or deciphering the executable’s sections. The unpacked binary can then be reconstructed, by dumping the recovered sections into a new executable and (usually) rebuilding the imports section from the recovered IAT(Import Address Table).
This can be accomplished in many ways including:
- Debugging manually and using plugins such as Scylla to reconstruct the imports section
- Python scripting leveraging Windows debugging libraries like winappdbg and executable file format libraries like pefile
- Intel Pintools dynamically instrumenting the binary at run-time (JIT instrumentation mode recommended to avoid integrity checks)
Expectedly, these approaches can be thwarted by anti-debug mechanisms and various detection mechanisms which, in turn, can be evaded via more debugger plugins such as ScyllaHide or by implementing various hooks such as those highlighted by ICPin. Finally, the original entry point of the application can usually be identified by its immediate calls to canonical C++ language’s internal initialization functions such as _initterm() and _initterm_e.
While the dynamic method is usually sufficient, the below samples highlight automated implementations that were successfully used via a python script to handle a simple packer that did not require imports rebuilding, and a versatile (albeit slower) dynamic execution engine implementation allowing a more granular approach, fit to uncover specific behaviors.
Control Flow Flattening
Once unpacked, the binary under investigation exposes a number of functions obfuscated using control flow graph (CFG) flattening, a variety of antidebug mechanisms, and integrity checks. Those can be identified as a preliminary step by running instrumented under ICPin (sample output below).
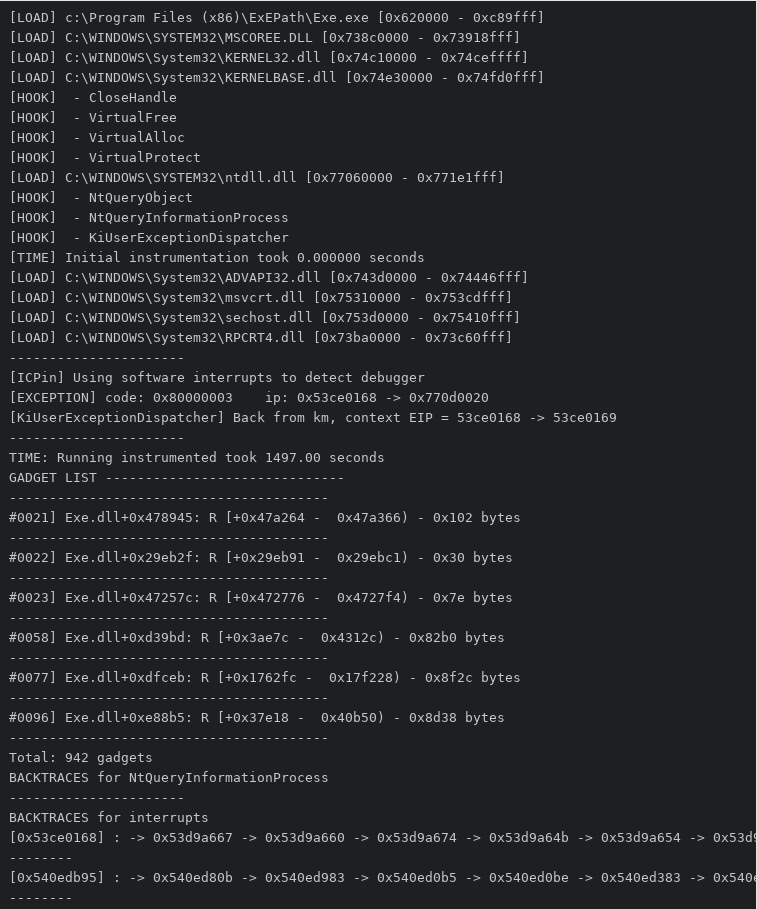
Overview
When disassembled, the CFG of each obfuscated function exhibits the pattern below: a state variable has been added to the original flow, which gets initialized in the function prologue and the branching structure has been replaced by a loop of pointer table-based dispatchers (highlighted in white).
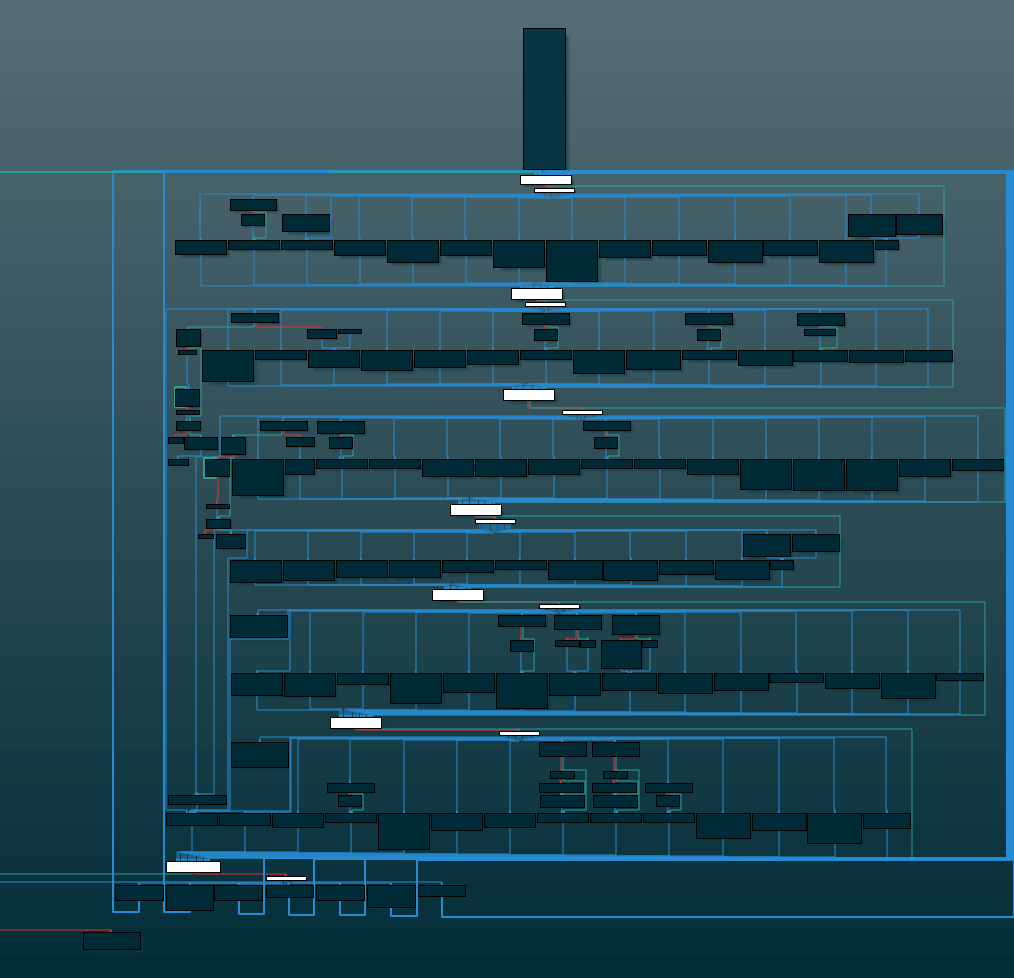
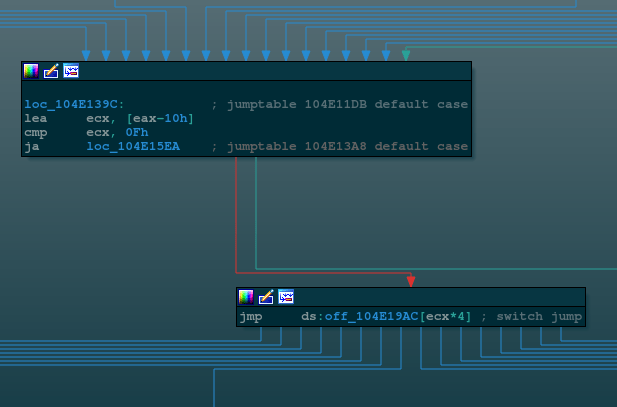
Each dispatch loop level contains between 2 and 16 indirect jumps to basic blocks (BBLs) actually implementing the function’s logic.
There are a number of ways to approach this problem, but the CFG flattening implemented here can be handled using a fully symbolic approach that does not require a dynamic engine, nor a real memory context. The first step is, for each function, to identify the loop using a loop-matching algorithm, then run a symbolic engine through it, iterating over all the possible index values and building an index-to-offset map, with the original function’s logic implemented within the BBL-chains located between the blocks belonging to the loop:

Real Destination(s) Recovery
The following steps consist of leveraging the index-to-offset map to reconnect these BBL-chains with each other, and recreate the original control-flow graph. As can be seen in the captures below, the value of the state variable is set using instruction-level obfuscation. Some BBL-chains only bear a static possible destination which can be swiftly evaluated.
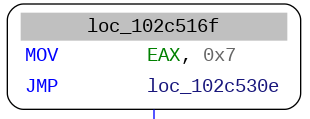

For dynamic-destination BBL-chains, once the register used as a state variable has been identified, the next step is to identify the determinant symbols, i.e, the registers and memory locations (globals or local variables) that affect the value of the state register when re-entering the dispatch loop.

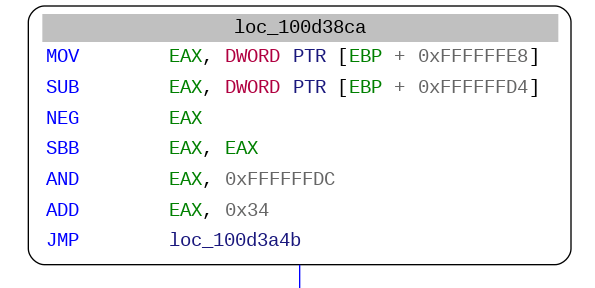
This can be accomplished by computing the intermediate language representation (IR) of the assembly flow graph (or BBLs) and building a dependency graph from it. Here we are taking advantage of a limitation of the obfuscator: the determinants for multi-destination BBLs are always contained within the BBL subgraph formed between two dispatchers.
With those determinants identified, the task that remains is to identify what condition these determinants are fulfilling, as well as what destinations in code we jump to once the condition has been evaluated. The Z3 SMT solver from Microsoft is traditionally used around dynamic symbolic engines (DSE) as a means to finding input values leading to new paths. Here, the deobfusactor uses its capabilities to identify the type of comparison the instructions are replacing.
For example, for the equal pattern, the code asks Z3 if 2 valid destination indexes (D1 and D2) exist such that:
- If the determinants are equal, the value of the state register is equal to D1
- If the determinants are different, the value of the state register is equal to D2
Finally, the corresponding instruction can be assembled and patched into the assembly, replacing the identified patterns with equivalent assembly sequences such as the ones below, where
- mod0 and mod1 are the identified determinants
- #SREG is the state register, now free to be repurposed to store the value of one of the determinants (which may be stored in memory):
- #OFFSET0 is the offset corresponding to the destination index if the tested condition is true
- #OFFSET1 is the offset corresponding to the destination index if the tested condition is false
class EqualPattern(Pattern): assembly = ''' MOV #SREG, mod0 CMP #SREG, mod1 JZ #OFFSET0 NOP JMP #OFFSET1 ''' class UnsignedGreaterPattern(Pattern): assembly = ''' MOV #SREG, mod0 CMP #SREG, mod1 JA #OFFSET0 NOP JMP #OFFSET1 ''' class SignedGreaterPattern(Pattern): assembly = ''' MOV #SREG, mod0 CMP #SREG, mod1 JG #OFFSET0 NOP JMP #OFFSET1 '''
The resulting CFG, since every original block has been reattached directly to its real target(s), effectively separates the dispatch loop from the significant BBLs. Below is the result of this first pass against a sample function:
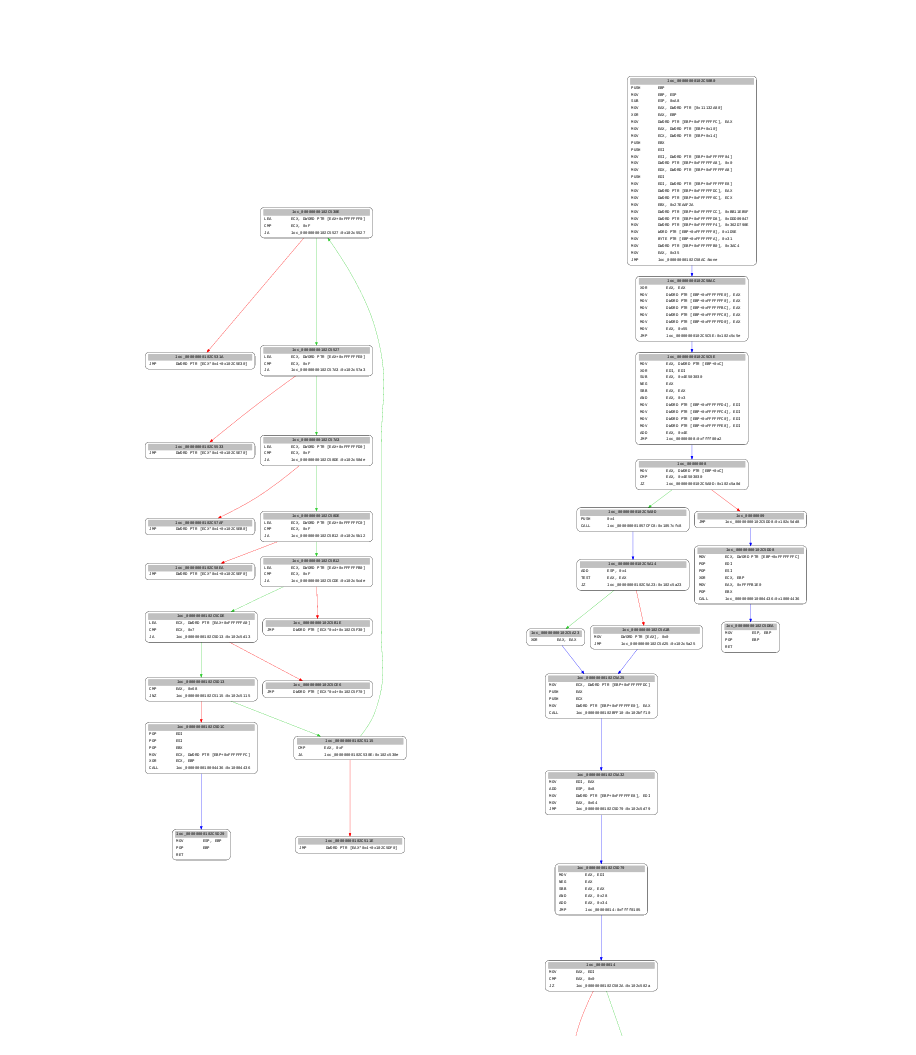
This approach does not aim at handling all possible theoretical cases; it takes advantage of the fact that the obfuscator only transforms a small set of arithmetic operations.
Integrity Check Removal
Once the flow graph has been unflattened, the next step is to remove the integrity checks. These can mostly be identified using a simple graph matching algorithm (using Miasm’s “MatchGraphJoker” expressions) which also constitutes a weakness in the obfuscator. In order to account for some corner cases, the detection logic implemented here involves symbolically executing the identified loop candidates, and recording their reads against the .text section in order to provide a robust identification.
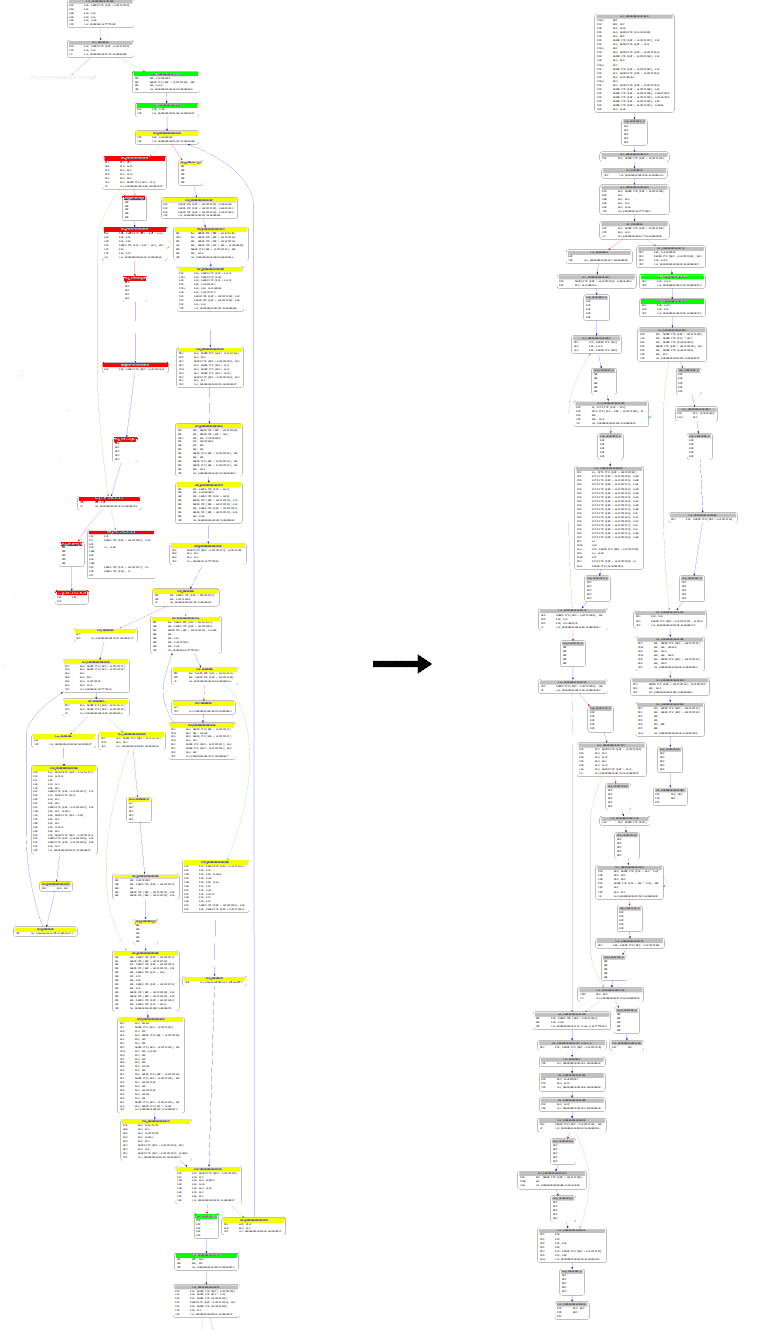
On the above graph, the hash verification flow is highlighted in yellow and the failure case (in this case, sending the execution to an address with invalid instructions) in red. Once the loop has been positively identified, the script simply links the green basic blocks to remove the hash check entirely.
“Dead” Instructions Removal
The resulting assembly is unflattened, and does not include the integrity checks anymore, but still includes a number of “dead” instructions which do not have any effect on the function’s logic and can be removed. For example, in the sample below, the value of EAX is not accessed between its first assignment and its subsequent ones. Consequently, the first assignment of EAX, regardless of the path taken, can be safely removed without altering the function’s logic.
start:
MOV EAX, 0x1234
TEST EBX, EBX
JNZ path1
path0:
XOR EAX, EAX
path1:
MOV EAX, 0x1
Using a dependency graph (depgraph) again, but this time, keeping a map of ASM <-> IR (one-to-many), the following pass removes the assembly instructions for which the depgraph has determined all corresponding IRs are non-performative.
Finally, the framework-provided simplifications, such as bbl-merger can be applied automatically to each block bearing a single successor, provided the successor only has a single predecessor. The error paths can also be identified and “cauterized”, which should be a no-op since they should never be executed but smoothen the rebuilding of the executable.
A Note On Antidebug Mechanisms
While a number of canonical anti-debug techniques were identified in the samples; only a few will be covered here as the techniques are well-known and can be largely ignored.
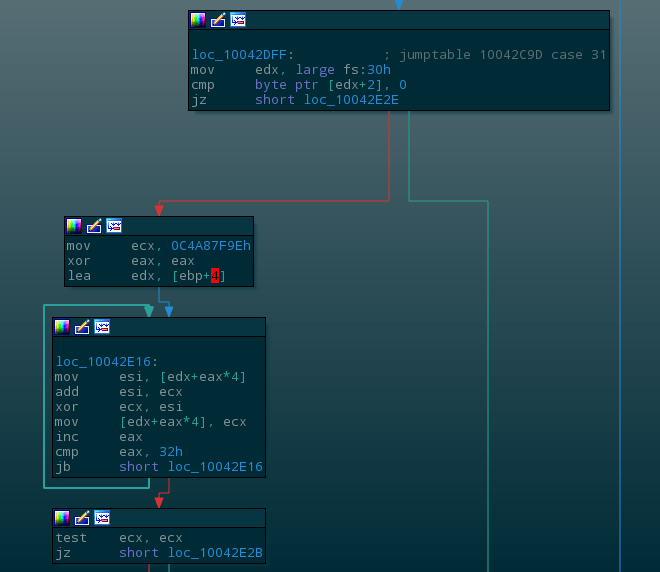
PEB->isBeingDebugged
In the example below, the function checks the PEB for isBeingDebugged (offset 0x2) and send the execution into a stack-mangling loop before continuing execution which is leads to a certain crash, obfuscating context from a naive debugging attempt.
Debug Interrupts
Another mechanism involves debug software interrupts and vectored exception handlers, but is rendered easily comprehensible once the function has been processed. The code first sets two local variables to pseudorandom constant values, then registers a vectored exception handler via a call to AddVectoredExceptionHandler. An INT 0x3 (debug interrupt) instruction is then executed (via the indirect call to ISSUE_INT3_FN), but encoded using the long form of the instruction: 0xCD 0x03.
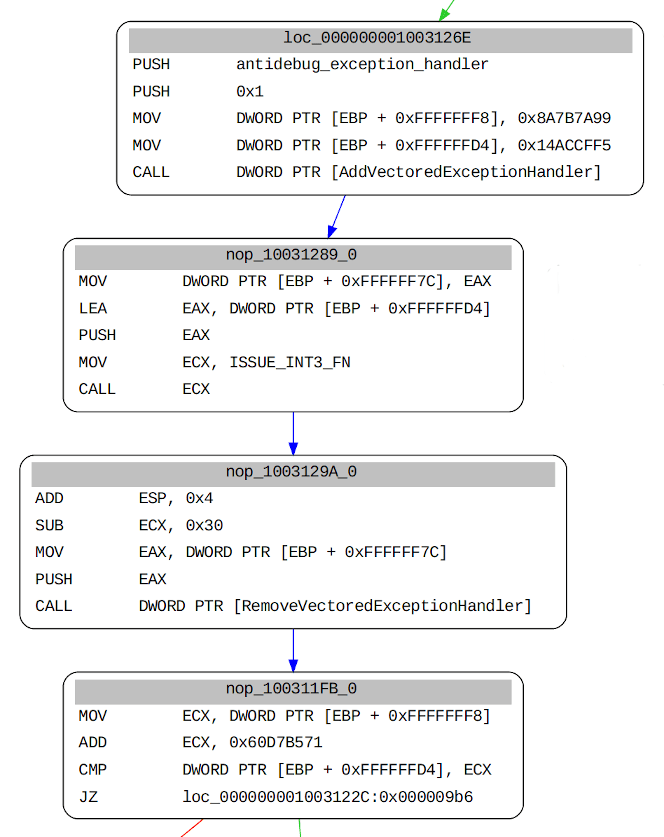
After executing the INT 0x3 instruction, the code flow is resumed in the exception handler as can be seen below.
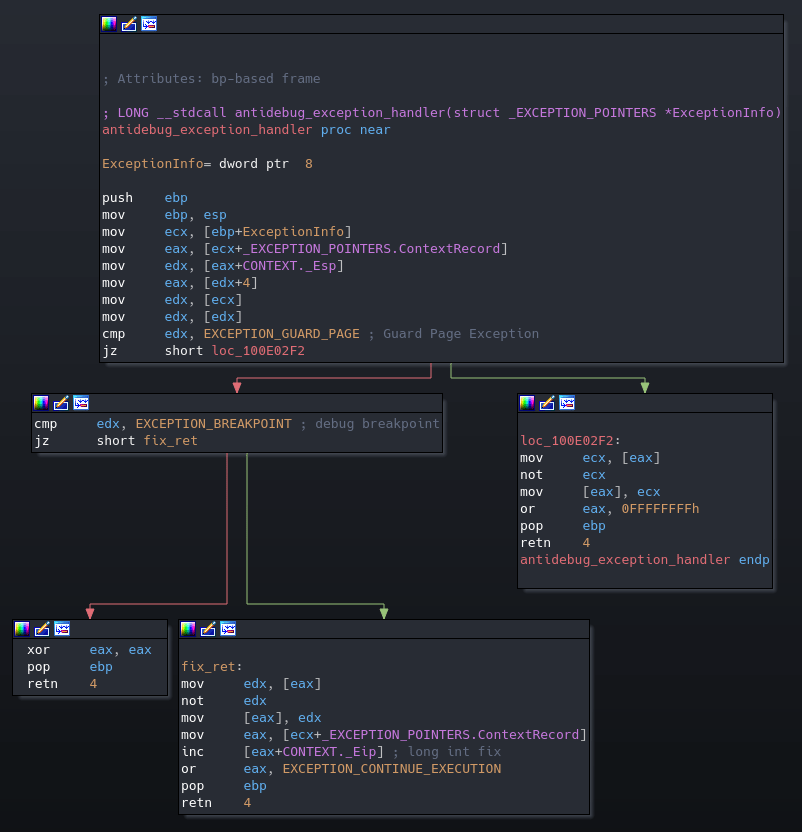
If the exception code from the EXCEPTION_RECORD structure is a debug breakpoint, a bitwise NOT is applied to one of the constants stored on stack. Additionally, the Windows interrupt handler handles every debug exception assuming they stemmed from executing the short version of the instruction (0xCC), so were a debugger to intercept the exception, those two elements need to be taken into consideration in order for execution to continue normally.
Upon continuing execution, a small arithmetic operation checks that the addition of one of the initially set constants (0x8A7B7A99) and a third one (0x60D7B571) is equal to the bitwise NOT of the second initial constant (0x14ACCFF5), which is the operation performed by the exception handler.
0x8A7B7A99 + 0x60D7B571 == 0xEB53300AA == ~0x14ACCFF5
A variant using the same exception handler operates in a very similar manner, substituting the debug exception with an access violation triggered via allocating a guard page and accessing it (this behavior is also flagged by ICPin).
Rebuilding The Executable
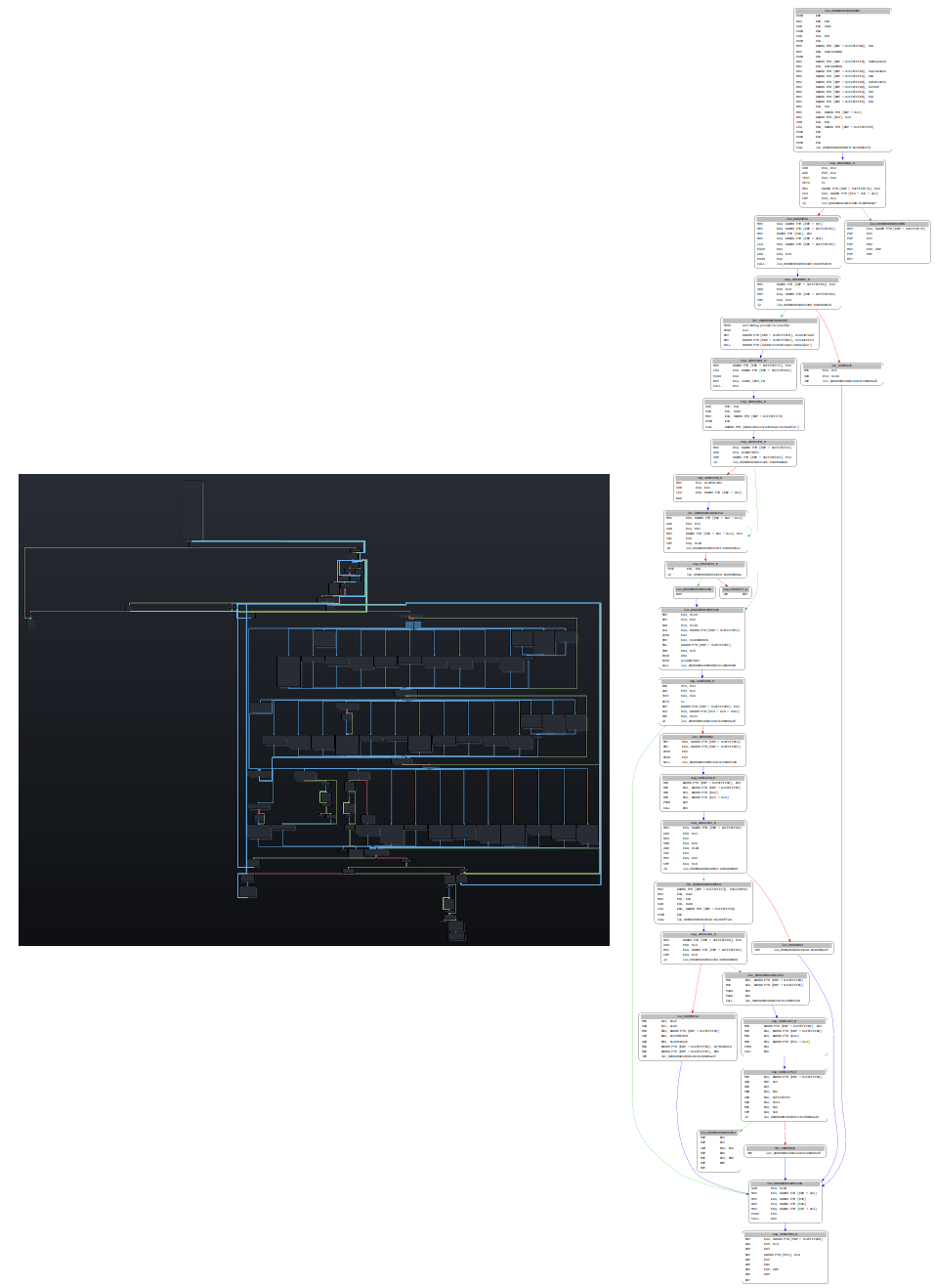
Once all the passes have been applied to all the obfuscated functions, the patches can be recorded, then applied to a free area of the new executable, and a JUMP is inserted at the function’s original offset.
Example of a function before and after deobfuscation:
Obfuscator’s Integrity Checking Internals
It is generally unnecessary to dig into the details of an obfuscator’s integrity checking mechanism; most times, as described in the previous example, identifying its location or expected result is sufficient to disable it. However, this provides a good opportunity to demonstrate the use of a DSE to address an obfuscator’s internals – theoretically its most hardened part.
ICPin output immediately highlights a number of code locations performing incremental reads on addresses in the executable’s .text section. Some manual investigation of these code locations points us to the spot where a function call or branching instruction switches to the obfuscated execution flow. However, there are no clearly defined function frames and the entire set of executed instructions is too large to display in IDA.
In order to get a sense of the execution flow, a simple jitter callback can be used to gather all the executed blocks as the engine runs through the code. Looking at the discovered blocks, it becomes apparent that the code uses conditional instructions to alter the return address on the stack, and hides its real destination with opaque predicates and obfuscated logic.
Starting with that information, it would be possible to take a similar approach as in the previous example and thoroughly rebuild the IR CFG, apply simplifications, and recompile the new assembly using LLVM. However, in this instance, armed with the knowledge that this obfuscated code implements an integrity check, it is advantageous to leverage the capabilities of a DSE.
A CFG of the obfuscated flow can still be roughly computed, by recording every block executed and adding edges based on the tracked destinations. The stock simplifications and SSA form can be used to obtain a graph of the general shape below:

Deciphering The Data Blobs
On a first run attempt, one can observe 8-byte reads from blobs located in two separate memory locations in the .text section, which are then processed through a loop (also conveniently identified by the tracking engine). With the memX symbols representing constants in memory, and blob0 representing the sequentially read input from a 32bit ciphertext blob, the symbolic values extracted from the blobs look as follows, looping 32 times:
res = (blob0 + ((mem1 ^ mem2)*mul) + sh32l((mem1 ^ mem2), 0x5)) ^ (mem3 + sh32l(blob0, 0x4)) ^ (mem4 + sh32r(blob0, 0x5))
Inspection of the values stored at memory locations mem1 and mem2 reveals the following constants:
@32[0x1400DF45A]: 0xA46D3BBF @32[0x14014E859]: 0x3A5A4206 0xA46D3BBF^0x3A5A4206 = 0x9E3779B9
0x9E3779B9 is a well-known nothing up my sleeve number, based on the golden ratio, and notably used by RC5. In this instance however, the expression points at another Feistel cipher, TEA, or Tiny Encryption Algorithm:
void decrypt (uint32_t v[2], const uint32_t k[4]) {
uint32_t v0=v[0], v1=v[1], sum=0xC6EF3720, i; /* set up; sum is 32*delta */
uint32_t delta=0x9E3779B9; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
}
v[0]=v0; v[1]=v1;
}
Consequently, the 128-bit key can be trivially recovered from the remaining memory locations identified by the symbolic engine.
Extracting The Offset Ranges
With the decryption cipher identified, the next step is to reverse the logic of computing ranges of memory to be hashed. Here again, the memory tracking execution engine proves useful and provides two data points of interest:
– The binary is not hashed in a continuous way; rather, 8-byte offsets are regularly skipped
– A memory region is iteratively accessed before each hashing
Using a DSE such as this one, symbolizing the first two bytes of the memory region and letting it run all the way to the address of the instruction that reads memory, we obtain the output below (edited for clarity):
-- MEM ACCESS: {BLOB0 0x7F 0 8, 0x0 8 64} + 0x140000000
# {BLOB0 0 8, 0x0 8 32} 0x80 = 0x0
...
-- MEM ACCESS: {(({BLOB1 0 8, 0x0 8 32} 0x7F) << 0x7) | {BLOB0 0x7F 0 8, 0x0 8 32} 0 32, 0x0 32 64} + 0x140000000
# 0x0 = ({BLOB0 0 8, 0x0 8 32} 0x80)?(0x0,0x1)
# ((({BLOB1 0 8, 0x0 8 32} 0x7F) << 0x7) | {BLOB0 0x7F 0 8, 0x0 8 32}) == 0xFFFFFFFF = 0x0
...
The accessed memory’s symbolic addresses alone provide a clear hint at the encoding: only 7 of the bits of each symbolized byte are used to compute the address. Looking further into the accesses, the second byte is only used if the first byte’s most significant bit is not set, which tracks with a simple unsigned integer base-128 compression. Essentially, the algorithm reads one byte at a time, using 7 bits for data, and using the last bit to indicate whether one or more byte should be read to compute the final value.
Identifying The Hashing Algorithm
In order to establish whether the integrity checking implements a known hashing algorithm, despite the static disassembly showing no sign of known constants, a memory tracking symbolic execution engine can be used to investigate one level deeper. Early in the execution (running the obfuscated code in its entirety may take a long time), one can observe the following pattern, revealing well-known SHA1 constants.
0x140E34F50 READ @32[0x140D73B5D]: 0x96F977D0 0x140E34F52 READ @32[0x140B1C599]: 0xF1BC54D1 0x140E34F54 READ @32[0x13FC70]: 0x0 0x140E34F5A READ @64[0x13FCA0]: 0x13FCD0 0x140E34F5E WRITE @32[0x13FCD0]: 0x67452301 0x140E34F50 READ @32[0x140D73B61]: 0x752ED515 0x140E34F52 READ @32[0x140B1C59D]: 0x9AE37E9C 0x140E34F54 READ @32[0x13FC70]: 0x1 0x140E34F5A READ @64[0x13FCA0]: 0x13FCD0 0x140E34F5E WRITE @32[0x13FCD4]: 0xEFCDAB89 0x140E34F50 READ @32[0x140D73B65]: 0xF9396DD4 0x140E34F52 READ @32[0x140B1C5A1]: 0x6183B12A 0x140E34F54 READ @32[0x13FC70]: 0x2 0x140E34F5A READ @64[0x13FCA0]: 0x13FCD0 0x140E34F5E WRITE @32[0x13FCD8]: 0x98BADCFE 0x140E34F50 READ @32[0x140D73B69]: 0x2A1B81B5 0x140E34F52 READ @32[0x140B1C5A5]: 0x3A29D5C3 0x140E34F54 READ @32[0x13FC70]: 0x3 0x140E34F5A READ @64[0x13FCA0]: 0x13FCD0 0x140E34F5E WRITE @32[0x13FCDC]: 0x10325476 0x140E34F50 READ @32[0x140D73B6D]: 0xFB95EF83 0x140E34F52 READ @32[0x140B1C5A9]: 0x38470E73 0x140E34F54 READ @32[0x13FC70]: 0x4 0x140E34F5A READ @64[0x13FCA0]: 0x13FCD0 0x140E34F5E WRITE @32[0x13FCE0]: 0xC3D2E1F0
Examining the relevant code addresses (as seen in the SSA notation below), it becomes evident that, in order to compute the necessary hash constants, a simple XOR instruction is used with two otherwise meaningless constants, rendering algorithm identification less obvious from static analysis alone.

And the expected SHA1 constants are stored on the stack:
0x96F977D0^0xF1BC54D1 ==> 0x67452301 0x752ED515^0x9AE37E9C ==> 0XEFCDAB89 0xF9396DD4^0x6183B12A ==> 0X98BADCFE 0x2A1B81B5^0x3A29D5C3 ==> 0X10325476 0xFB95EF83^0x38470E73 ==> 0XC3D2E1F0
Additionally, the SHA1 algorithm steps can be further observed in the SSA graph, such as the ROTL-5 and ROTL-30 operations, plainly visible in the IL below.
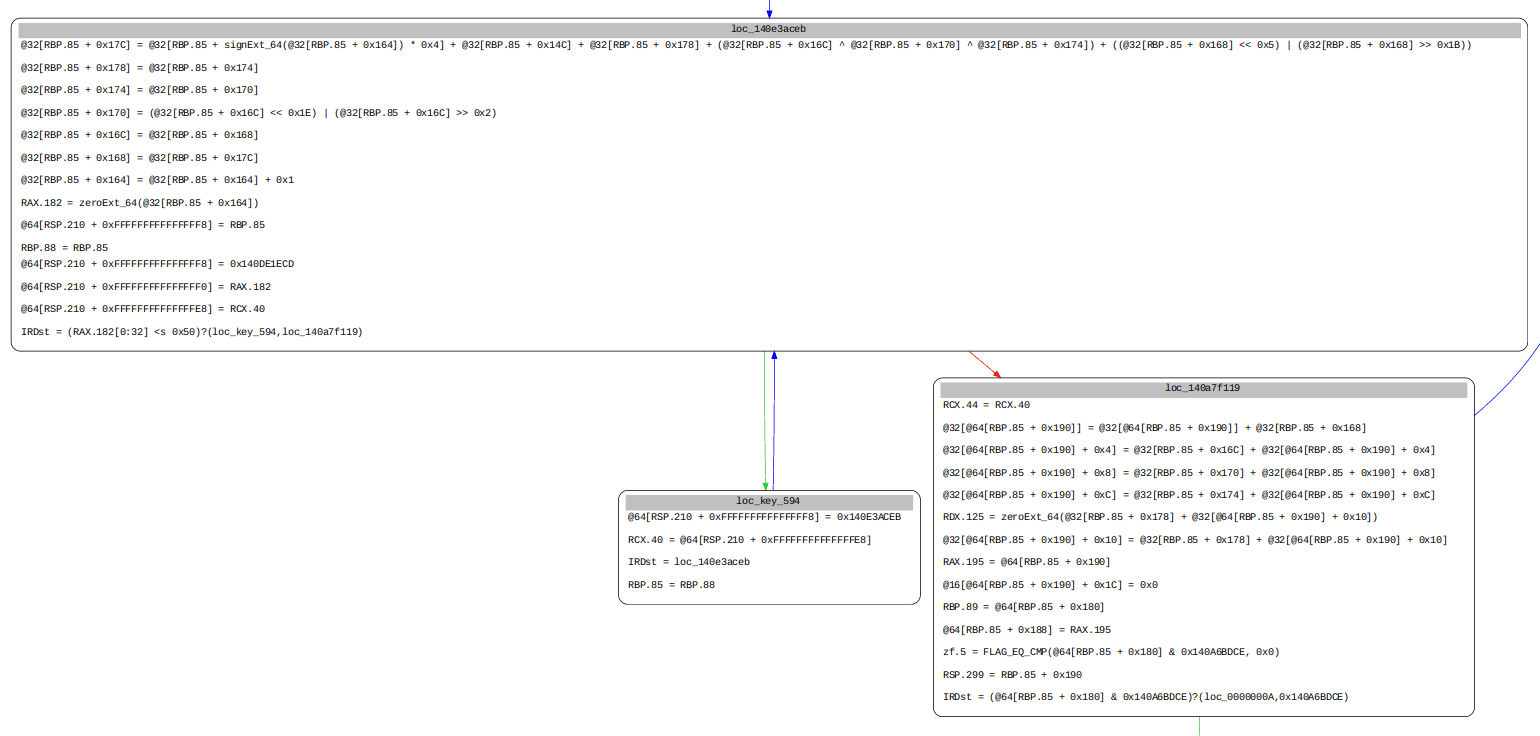
Final Results
The entire integrity checking logic recovered from the obfuscator implemented in Python below was verified to produce the same digest, as when running under the debugger, or a straightforward LLVM jitter. The parse_ranges() function handles the encoding, while the accumulate_bytes() generator handles the deciphering and processing of both range blobs and skipped offset blobs.
Once the hashing of the memory ranges dictated by the offset table has completed, the 64bit values located at the offsets deciphered from the second blob are subsequently hashed. Finally, once the computed hash value has been successfully compared to the valid digest stored within the RWX .text section of the executable, the execution flow is deemed secure and the obfuscator proceeds to decipher protected functions within the .text section.
def parse_ranges(table):
ranges = []
rangevals = []
tmp = []
for byte in table:
tmp.append(byte)
if not byte 0x80:
val = 0
for i,b in enumerate(tmp):
val |= (b 0x7F)<<(7*i)
rangevals.append(val)
tmp = [] # reset
offset = 0
for p in [(rangevals[i], rangevals[i+1]) for i in range(0, len(rangevals), 2)]:
offset += p[0]
if offset == 0xFFFFFFFF:
break
ranges.append((p[0], p[1]))
offset += p[1]
return ranges
def accumulate_bytes(r, s):
# TEA Key is 128 bits
dw6 = 0xF866ED75
dw7 = 0x31CFE1EF
dw4 = 0x1955A6A0
dw5 = 0x9880128B
key = struct.pack('IIII', dw6, dw7, dw4, dw5)
# Decipher ranges plaintext
ranges_blob = pe[pe.virt2off(r[0]):pe.virt2off(r[0])+r[1]]
ranges = parse_ranges(Tea(key).decrypt(ranges_blob))
# Decipher skipped offsets plaintext (8bytes long)
skipped_blob = pe[pe.virt2off(s[0]):pe.virt2off(s[0])+s[1]]
skipped_decrypted = Tea(key).decrypt(skipped_blob)
skipped = sorted(
[int.from_bytes(skipped_decrypted[i:i+4], byteorder='little', signed=False)
for i in range(0, len(skipped_decrypted), 4)][:-2:2]
)
skipped_copy = skipped.copy()
next_skipped = skipped.pop(0)
current = 0x0
for rr in ranges:
current += rr[0]
size = rr[1]
# Get the next 8 bytes to skip
while size and next_skipped and next_skipped = 0
yield blob
current = next_skipped+8
next_skipped = skipped.pop(0) if skipped else None
blob = pe[pe.rva2off(current):pe.rva2off(current)+size]
yield blob
current += len(blob)
# Append the initially skipped offsets
yield b''.join(pe[pe.rva2off(rva):pe.rva2off(rva)+0x8] for rva in skipped_copy)
return
def main():
global pe
hashvalue = hashlib.sha1()
hashvalue.update(b'x7Bx0Ax97x43')
with open(argv[1], "rb") as f:
pe = PE(f.read())
accumulator = accumulate_bytes((0x140A85B51, 0xFCBCF), (0x1409D7731, 0x12EC8))
# Get all hashed bytes
for blob in accumulator:
hashvalue.update(blob)
print(f'SHA1 FINAL: {hashvalue.hexdigest()}')
return
Disclaimer
None of the samples used in this publication were part of an NCC Group engagement. They were selected from publicly available binaries whose obfuscators exhibited features similar to previously encountered ones.
Due to the nature of this material, specific content had to be redacted, and a number of tools that were created as part of this effort could not be shared publicly.
Despite these limitations, the author hopes the technical content shared here is sufficient to provide the reader with a stimulating read.
