Outline
- 1. Introduction
- 2. How does MT19937 PRNG work?
- 3. Using Neural Networks to model the MT19937 PRNG
- 4. Improving MT Algorithm
- 5. Conclusion
1. Introduction
In part 1 of this post, we showed how to train a Neural Network to generate the exact sequence of a relatively simple pseudo-random number generator (PRNG), namely xorshift128. In that PRNG, each number is totally dependent on the last four generated numbers (which form the random number internal state). Although ML had learned the hidden internal structure of the xorshift128 PRNG, it is a very simple PRNG that we used as a proof of concept.
The same concept applies to a more complex structured PRNG, namely Mersenne Twister (MT). MT is by far the most widely used general-purpose (but still: not cryptographically secure) PRNG [1]. It can have a very long period of 32bit words with a statistically uniform distribution. There are many variants of the MT PRNG that follows the same algorithm but differ in the constants and configurations of the algorithm. The most commonly used variant of MT is MT19937. Hence, for the rest of this article, we will focus more on this variant of MT.
To crack the MT algorithm, we need first to examine how it works. In the next section, we will discuss how MT works.
** Editor’s Note: How does this relate to security? While both the research in this blog post (and that of Part 1 in this series) looks at a non-cryptographic PRNG, we are interested, generically, in understanding how machine learning-based approaches to finding latent patterns within functions presumed to be generating random output could work, as a prerequisite to attempting to use machine learning to find previously-unknown patterns in cryptographic (P)RNGs, as this could potentially serve as an interesting supplementary method for cryptanalysis of these functions. Here, we show our work in beginning to explore this space, extending the approach used for xorshift128 to Mersenne Twister, a non-cryptographic PRNG sometimes mistakenly used where a cryptographically-secure PRNG is required. **
2. How does MT19937 PRNG work?
MT can be considered as a twisted form of the generalized Linear-feedback shift register (LFSR). The idea of LFSR is to use a linear function, such as XOR, with the old register value to get the register’s new value. In MT, the internal state is saved in the form of a sequence of 32-bit words. The size of the internal state is different based on the MT variant, which in the case of MT19937 is 624. The pseudocode of MT is listed below as shared in Wikipedia.
// Create a length n array to store the state of the generator
int[0..n-1] MT
int index := n+1
const int lower_mask = (1 << r) - 1 // That is, the binary number of r 1's
const int upper_mask = lowest w bits of (not lower_mask)
// Initialize the generator from a seed
function seed_mt(int seed) {
index := n
MT[0] := seed
for i from 1 to (n - 1) { // loop over each element
MT[i] := lowest w bits of (f * (MT[i-1] xor (MT[i-1] >> (w-2))) + i)
}
}
// Extract a tempered value based on MT[index]
// calling twist() every n numbers
function extract_number() {
if index >= n {
if index > n {
error "Generator was never seeded"
// Alternatively, seed with constant value; 5489 is used in reference C code[53]
}
twist()
}
int y := MT[index]
y := y xor ((y >> u) and d)
y := y xor ((y << s) and b)
y := y xor ((y << t) and c)
y := y xor (y >> l)
index := index + 1
return lowest w bits of (y)
}
// Generate the next n values from the series x_i
function twist() {
for i from 0 to (n-1) {
int x := (MT[i] and upper_mask)
+ (MT[(i+1) mod n] and lower_mask)
int xA := x >> 1
if (x mod 2) != 0 { // lowest bit of x is 1
xA := xA xor a
}
MT[i] := MT[(i + m) mod n] xor xA
}
index := 0
} The first function is seed_mt, used to initialize the 624 state values using the initial seed and the linear XOR function. This function is straightforward, but we will not get in-depth of its implementation as it is irrelevant to our goal. The main two functions we have are extract_number and twist. extract_number function is called every time we want to generate a new random value. It starts by checking if the state is not initialized; it either initializes it by calling seed_mt with a constant seed or returns an error. Then the first step is to call the twist function to twist the internal state, as we will describe later. This twist is also called every 624 calls to the extract_number function again. After that, the code uses the number at the current index (which starts with 0 up to 623) to temper one word from the state at that index using some linear XOR, SHIFT, and AND operations. At the end of the function, we increment the index and return the tempered state value.
The twist function changes the internal states to a new state at the beginning and after every 624 numbers generated. As we can see from the code, the function uses the values at indices i, i+1, and i+m to generate the new value at index i using some XOR, SHIFT, and AND operations similar to the tempering function above.
Please note that w, n, m, r, a, u, d, s, b, t, c, l, and f are predefined constants for the algorithm that may change from one version to another. The values of these constants for MT19937 are as follows:
- (w, n, m, r) = (32, 624, 397, 31)
- a = 9908B0DF16
- (u, d) = (11, FFFFFFFF16)
- (s, b) = (7, 9D2C568016)
- (t, c) = (15, EFC6000016)
- l = 18
- f = 1812433253
3. Using Neural Networks to model the MT19937 PRNG
As we saw in the previous section, MT can be split into two main steps, twisting and tempering steps. The twisting step only happens once every n calls to the PRNG (where n equals 624 in MT19937) to twist the old state into a new state. The tempering step happens with each number generated to convert one of the 624 states to a random number. Hence, we are planning to use two NN models to learn each step separately. Then we will use the two models to reverse the whole PRNG by using the reverse tempering model to get from a generated number to its internal state then use the twisting model to produce the new state. Then, we can temper the generated state to get to the expected new PRNG number.
3.1 Using NN for State Twisting
After checking the code listing for the twisting function line 46, we can see that the new state at the position, i, depends on the variable xA and the value of the old state value at position (i + m), where m equals 397 in MT19937. Also, the value of xA depends on the value of the variable x and some constant a. And the value of the variable x depends on the old state’s values at positions i and i + 1.
Hence, we can deduce that, and without getting into the details, each new twisted state depends on three old states as follows:
MT[i] = f(MT[i - 624], MT[i - 624 + 1], MT[i - 624 + m])
= f(MT[i - 624], MT[i - 623], MT[i - 227]) ( using m = 397 as in MT19937 )
We want to train an NN model to learn the function f hence effectively replicating the twisting step. To accomplish this, we have created a different function that generates the internal state (without tempering) instead of the random number. This allows us to correlate the internal states with each other, as described in the above formula.
3.1.1 Data Preparation
We have generated a sequence of 5,000,000 32bits words of states. We then formatted these states into three 32bits inputs and one 32bits output. This would create around a five million records dataset (5 million – 624). Then we split the data into training and testing sets, with only 100,000 records for the test set, and the rest of the data is used for training.
3.1.2 Neural Network Model Design
Our proposed model would have 96 inputs in the input layer to represent the old three states at the specific locations described in the previous equation, 32-bit each, and 32 outputs in the output layer to represent the new 32-bit state. The main hyperparameters that we need to decide are the number of neurons/nodes and hidden layers. We have tested different models’ structures with different hidden layers and a different number of neurons in each layer. Then we used Keras’ BayesianOptimization to select the optimal number of hidden layers/neurons along with other optimization parameters (such as learning rate, … etc.). We used a small subset of the training set as the training set for this optimization. We have got multiple promising model structures. Then, we used the smallest model structure that had the most promising result.
3.1.3 Optimizing the NN Inputs
After training multiple models, we noticed that the weights that connect the first 31-bit of the 96 input bits to the first hidden layer nodes are almost always close to zero. This implies that those bits have no effects on the output bits, and hence we can ignore them in our training. To check our observation with the MT implementation, we noticed that the state at position i is bitwise ANDed with a bitmask called upper_mask which, when we checked, has a value of 1 in the MSB and 0 for the rest when using r with the value of 31 as stated in MT19937. So, we only need the MSB of the state at position i. Hence, we can train our NN with only 65bits inputs instead of 96.
Hence, our neural network structure ended up with the following model structure (the input layer is ignored):
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 96) 6336 _________________________________________________________________ dense_1 (Dense) (None, 32) 3104 ================================================================= Total params: 9,440 Trainable params: 9,440 Non-trainable params: 0 _________________________________________________________________
As we can see, the number of the parameters (weights and biases) of the hidden layer is only 6,336 (65×96 weights + 96 biases), and the number of the parameters of the output layer is 3,104 (96×32 weights + 32 biases), which gets to a total of 9,440 parameters to train. The hidden layer activation function is relu, while the output layer activation function is sigmoid as we expect it to be a binary output. Here is the summary of the model parameters:
| Twisting Model | |
|---|---|
| Model Type | Dense Network |
| #Layers | 2 |
| #Neurons | 128 Dense |
| #Trainable Parameters | 9,440 |
| Activation Functions | Hidden Layer: relu Output Layer: sigmoid |
| Loss Function | binary_crossentropy |
3.1.4 Model Results
After a few hours and manual tweaking of the model architecture, we have trained a model that has achieved 100% bitwise accuracy for both the training and testing sets. To be more confident about what we have achieved, we have generated a new sample of 1000,000 states generated using a different seed than the one used to generate the previous data. We got the same result of 100% bitwise accuracy when we tested with the newly generated data.
This means that the model has learned the exact formula that relates each state to the three previous states. Hence if we got access to the three internal states at those specific locations, we could predict the next state. But, usually, we can get access only to the old random numbers, not the internal states. So, we need a different model that can reverse the generated tempered number to its equivalent internal state. Then we can use this model to create the new state. Then, we can use the normal tempering step to get to the new output. But before we get to that, let’s do model deep dive.
3.1.5 Model Deep Dive
This section will deep dive into the model to understand more what it has learned from the State relations data and if it matches our expectations.
3.1.5.1 Model First Layer Connections
As discussed in Section 2, each state depends on three previous states, and we also showed that we only need the MSB (most significant bit) of the first state; hence we had 65bits as input. Now, we would like to examine whether all 65 input bits have the same effects on the 64 output bits? In other words, do all the input bits have more or less the same importance for the outputs? We can use the NN weights that connect the 65 inputs in the input layer to the hidden layer, the 96 hidden nodes, of our trained model to determine the importance of each bit. The following figure shows the weights connecting each input, in x-axes, to the 96 hidden nodes in the hidden layer:
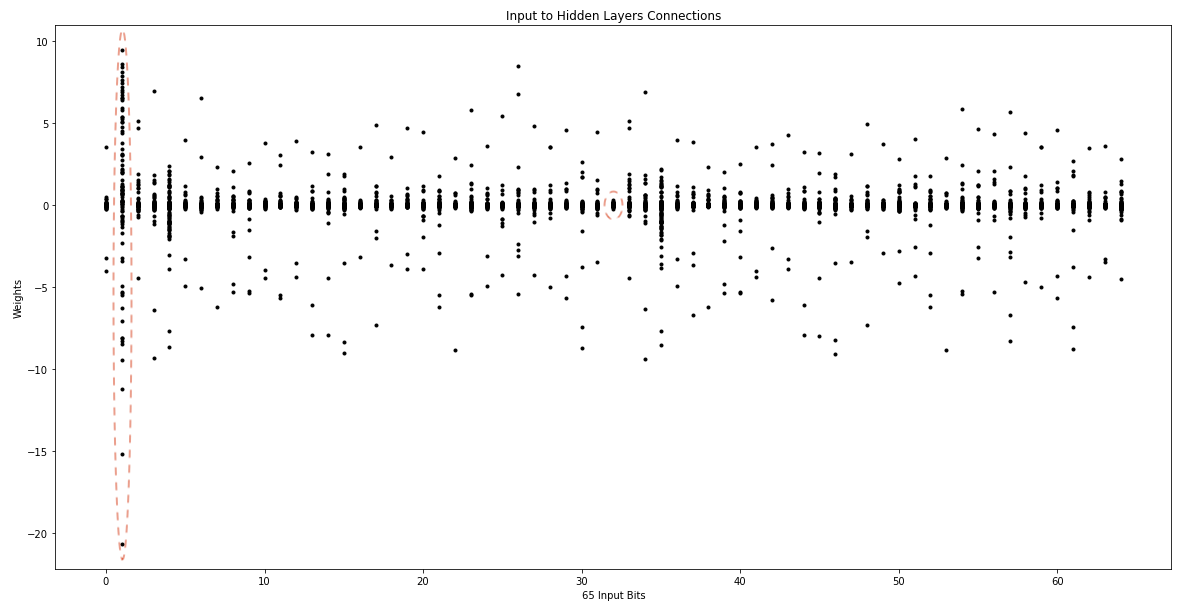
We can notice that the second bit, which corresponds to the second state LSB, is connected to many hidden layer nodes, implying that it affects multiple bits in the output. Comparing this observation against the code listed in Section 2 corresponds to the if-condition that checks the LSB bit, and based on its value, it may XOR the new state with a constant value that dramatically affects the new state.
We can also notice that the 33rd input, marked on the figure, is almost not connected to any hidden layer nodes as all the weights are close to zero. This can also be mapped to the code in line 12, where we bit masked the second state to 0x7FFFFFFF in MT19937, which basically neglects the MSB altogether.
3.1.5.2 The Logic Closed-Form from the State Twisting Model Output
After creating a model that can replicate the twist operation of the states, we would like to see if we can possibly get to the logic closed form using the trained model. Of course, we can derive the closed-form by building all the 65bit input variations and testing each input combination’s outputs (2^65) and derive the closed-form. But this approach is tedious and requires lots of evaluations. Instead, we can test the effect of each input on each output separately. This can be done by using the training set and sticking each input bit individually, one time at 0 and one time at 1, and see which bits in the output are affected. This will show how which bits in the inputs affecting each bit in the output. For example, when we checked the first input, which corresponds to MSB of the first state, we found it only affects bit 30 in the output. The following table shows the effect of each input bit on each output bit:
| Input Bits | Output Bits |
|---|---|
| 0 | [30] |
| 1 | [0, 1, 2, 3, 4, 6, 7, 12, 13, 15, 19, 24, 27, 28, 31] |
| 2 | [0] |
| 3 | [1] |
| 4 | [2] |
| 5 | [3] |
| 6 | [4] |
| 7 | [5] |
| 8 | [6] |
| 9 | [7] |
| 10 | [8] |
| 11 | [9] |
| 12 | [10] |
| 13 | [11] |
| 14 | [12] |
| 15 | [13] |
| 16 | [14] |
| 17 | [15] |
| 18 | [16] |
| 19 | [17] |
| 20 | [18] |
| 21 | [19] |
| 22 | [20] |
| 23 | [21] |
| 24 | [22] |
| 25 | [23] |
| 26 | [24] |
| 27 | [25] |
| 28 | [26] |
| 29 | [27] |
| 30 | [28] |
| 31 | [29] |
| 32 | [] |
| 33 | [0] |
| 34 | [1] |
| 35 | [2] |
| 36 | [3] |
| 37 | [4] |
| 38 | [5] |
| 39 | [6] |
| 40 | [7] |
| 41 | [8] |
| 42 | [9] |
| 43 | [10] |
| 44 | [11] |
| 45 | [12] |
| 46 | [13] |
| 47 | [14] |
| 48 | [15] |
| 49 | [16] |
| 50 | [17] |
| 51 | [18] |
| 52 | [19] |
| 53 | [20] |
| 54 | [21] |
| 55 | [22] |
| 56 | [23] |
| 57 | [24] |
| 58 | [25] |
| 59 | [26] |
| 60 | [27] |
| 61 | [28] |
| 62 | [29] |
| 63 | [30] |
| 64 | [31] |
We can see that inputs 33 to 64, which corresponds to the last state, are affecting bits 0 to 31 in the output. We can also see that inputs 2 to 31, which corresponds to the second state from bit 1 to bit 30 (ignoring the LSB and MSB), affect bits 0 to 29 in the output. And as we know, we are using the XOR logic function in the state evaluation. We can formalize the closed-form as follows (ignoring bit 0 and bit 1 in the input for now):
MT[i] = MT[i - 227] ^ ((MT[i - 623] 0x7FFFFFFF) >> 1)
This formula is so close to the result. We need to add the effect of input bits 0 and 1. For input number 0, which corresponds to the first state MSB, it is affecting bit 30. Hence we can update the above closed-form to be:
MT[i] = MT[i - 227] ^ ((MT[i - 623] 0x7FFFFFFF) >> 1) ^ ((MT[i - 624] 0x80000000) << 1)
Lastly, the first bit in the input, which corresponds to the second state LSB, affects 15 bits in the output. As we are using it in an XOR function, if this bit is 0, it does not affect the output, but if it has a value of one, it will affect all the listed 15bits (by XORing them). If we formulate these 15 bits into a hexadecimal value, we will get 0x9908B0DF (which corresponds to the constant a in MT19937). Then we can include this to the closed-form as follows:
MT[i] = MT[i - 227] ^ ((MT[i - 623] 0x7FFFFFFF) >> 1) ^ ((MT[i - 624] 0x80000000) << 1) ^ ((MT[i - 623] 1) * 0x9908B0DF)
So, if the LSB of the second state is 0, the result of the ANDing will be 0, and hence the multiplication will result in 0. But if the LSB of the second state is 1, the result of the ANDing will be 1, and hence the multiplication will result in 0x9908B0DF. This is equivalent to the if-condition in the code listing. We can rewrite the above equation to use the circular buffer as follows:
MT[i] = MT[(i + 397) % 624] ^ ((MT[(i + 1) % 624] 0x7FFFFFFF) >> 1) ^ ((MT[i] 0x80000000) << 1) ^ ((MT[(i + 1) % 624] 1) * 0x9908B0DF)
Now let’s check how to reverse the tempered numbers to the internal states using an ML model.
3.2 Using NN for State Tempering
We plan to train a neural network model for this phase to reverse the state tempering introduced in the code listing from line 10 to line 20. As we can see, a series of XORing and shifting is done to the state at the current index to generate the random number. So, we have updated the code to generate the state before and after the state tempering to be used as inputs and outputs for the Neural network.
3.2.1 Data Preparation
We have generated a sequence of 5,000,000 32 bit words of states and their tempered values. Then we used the tempered states as inputs and the original states as outputs. This would create a 5 million records dataset. Then we split the data into training and testing sets, with only 100,000 records for the test set, and the rest of the data is used for training.
3.2.2 Neural Network Model Design
Our proposed model would have 32 inputs in the input layer to represent the tempered state values and 32 outputs in the output layer to represent the original 32-bit state. The main hyperparameter that we need to decide is the number of neurons/nodes and hidden layers. We have tested different models’ structures with a different number of hidden layers and neurons in each layer, similar to what we did in the NN model before. We also used the smallest model structure that has the most promising result. Hence, our neural network structure ended up with the following model structure (the input layer is ignored):
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 640) 21120 _________________________________________________________________ dense_1 (Dense) (None, 32) 20512 ================================================================= Total params: 41,632 Trainable params: 41,632 Non-trainable params: 0 _________________________________________________________________
As we can see, the number of the parameters (weights and biases) of the hidden layer is only 21,120 (32×640 weights + 640 biases), and the number of the parameters of the output layer is 20,512 (640×32 weights + 32 biases), which gets to a total of 41,632 parameters to train. We can notice that this model is much bigger than the model for twisting as the operations done in tempering is much more complex than the operations done there. Similarly, the hidden layer activation function is relu, while the output layer activation function is sigmoid as we expect it to be a binary output. Here is the summary of the model parameters:
| Tempering Model | |
|---|---|
| Model Type | Dense Network |
| #Layers | 2 |
| #Neurons | 672 Dense |
| #Trainable Parameters | 41,632 |
| Activation Functions | Hidden Layer: relu Output Layer: sigmoid |
| Loss Function | binary_crossentropy |
3.2.3 Model Results
After manual tweaking of the model architecture, we have trained a model that has achieved 100% bitwise accuracy for both the training and testing sets. To be more confident about what we have achieved, we have generated a new sample of 1000,000 states and tempered states using a different seed than those used to generate the previous data. We got the same result of 100% bitwise accuracy when we tested with the newly generated data.
This means that the model has learned the exact inverse formula that relates each tempered state to its original state. Hence, we can use this model to reverse the generated numbers corresponding to the internal states we need for the first model. Then we can use the twisting model to get the new state. Then, we can use the normal tempering step to get to the new output. But before we get to that, let’s do a model deep dive.
3.2.4 Model Deep Dive
This section will deep dive into the model to understand more what it has learned from the State relations data and if it matches our expectations.
3.2.4.1 Model Layers Connections
After training the model, we wanted to test if any bits are not used or are less connected. The following figure shows the weights connecting each input, in x-axes, to the 640 hidden nodes in the hidden layer (each point represents a hidden node weight):
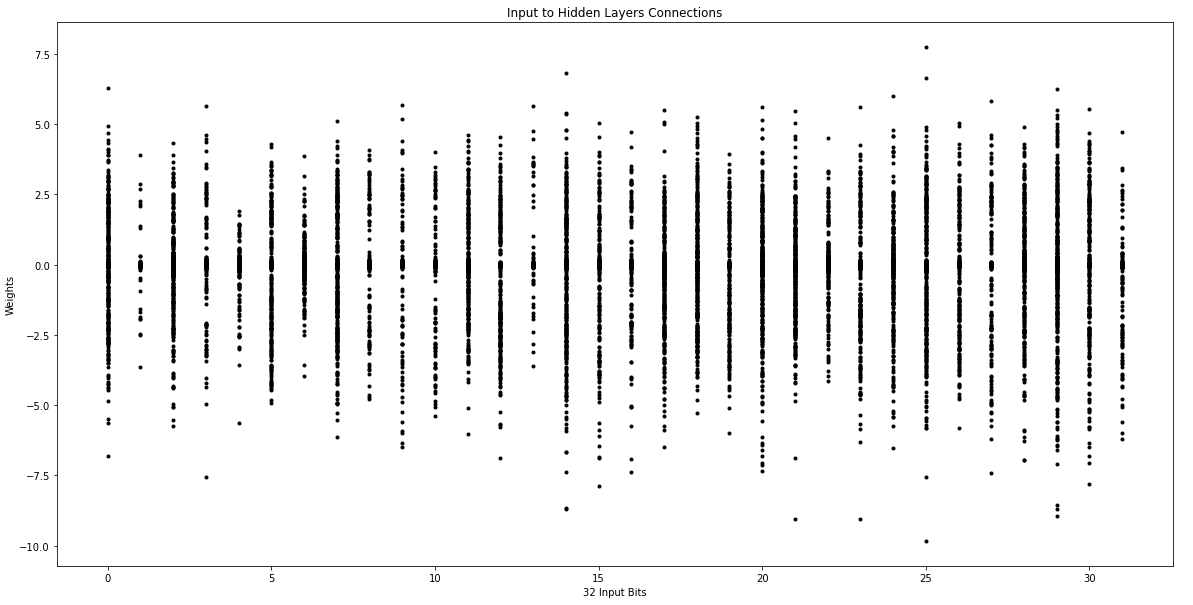
As we can see, each input bit is connected to many hidden nodes, which implies that each bit in the input has more or less weight like others. We also plot in the following figure the connections between the hidden layer and the output layer:
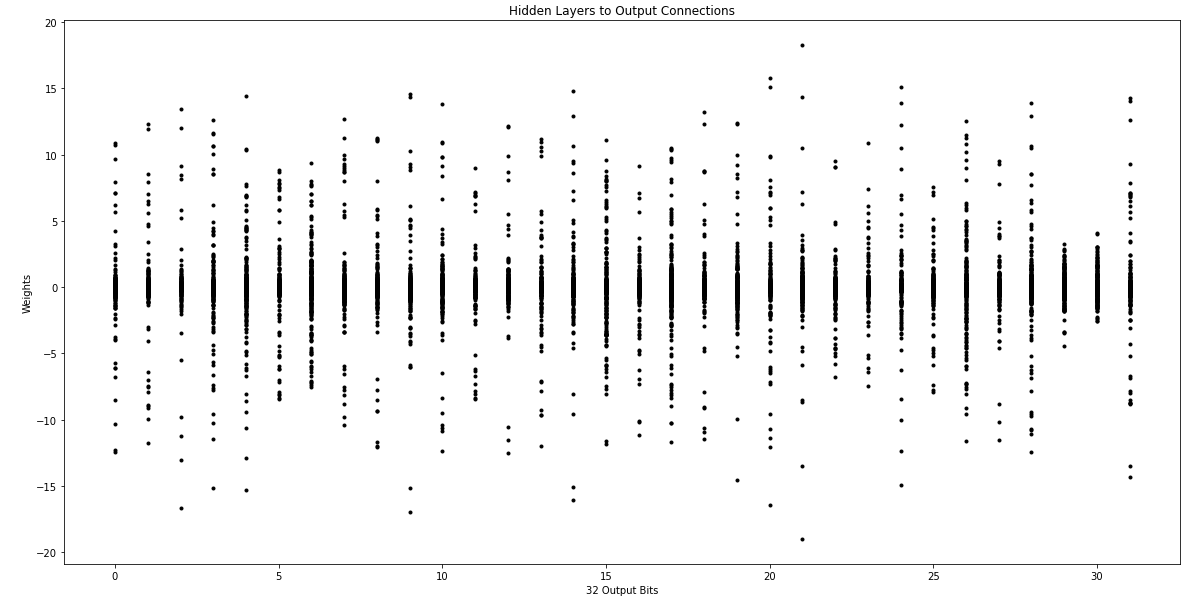
The same observation can be taken from the previous figure, except that maybe bits 29 and 30 are less connected than others, but they are still well connected to many hidden nodes.
3.2.4.2 The Logic Closed-Form from the State Tempering Model Output
In the same way, we did with the first model, we can derive a closed-form logic expression that reverses the tempering using the model output. But, instead of doing so, we can derive a closed-form logic expression that uses the generated numbers at the positions mentioned in the first part to reverse them to the internal states, generate the new states and then generate the new number in one step. So, we plan to connect three models of the reverse tempering models to one model that generates the new state and then temper the output to get to the newly generated number as shown in the following figure:
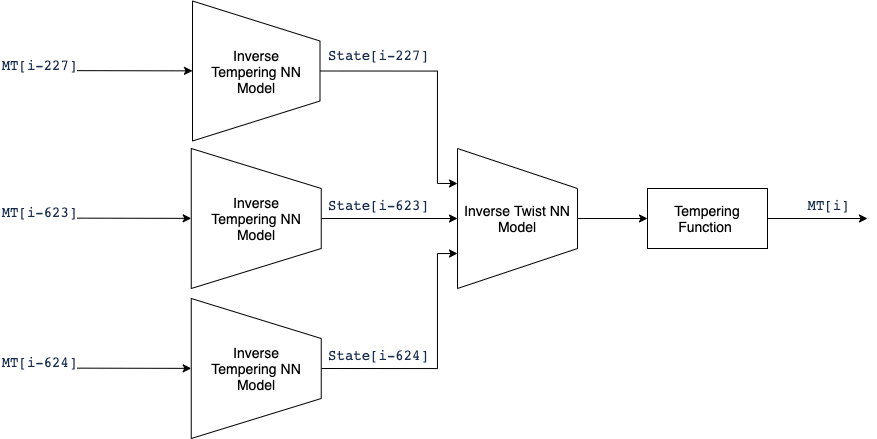
Now we have 3 x 32 bits inputs and 32 bits output. Using the same approach described before, we can test the effect of each input on each output separately. This will show how each bit in the input bits affecting each bit in the output bits. The following table shows the input-output relations:
| Input Index | Input Bits | Output Bits |
|---|---|---|
| 0 | 0 | [] |
| 0 | 1 | [] |
| 0 | 2 | [1, 8, 12, 19, 26, 30] |
| 0 | 3 | [] |
| 0 | 4 | [] |
| 0 | 5 | [] |
| 0 | 6 | [] |
| 0 | 7 | [] |
| 0 | 8 | [] |
| 0 | 9 | [1, 8, 12, 19, 26, 30] |
| 0 | 10 | [] |
| 0 | 11 | [] |
| 0 | 12 | [] |
| 0 | 13 | [] |
| 0 | 14 | [] |
| 0 | 15 | [] |
| 0 | 16 | [1, 8, 12, 19, 26, 30] |
| 0 | 17 | [1, 8, 12, 19, 26, 30] |
| 0 | 18 | [] |
| 0 | 19 | [] |
| 0 | 20 | [1, 8, 12, 19, 26, 30] |
| 0 | 21 | [] |
| 0 | 22 | [] |
| 0 | 23 | [] |
| 0 | 24 | [1, 8, 12, 19, 26, 30] |
| 0 | 25 | [] |
| 0 | 26 | [] |
| 0 | 27 | [1, 8, 12, 19, 26, 30] |
| 0 | 28 | [] |
| 0 | 29 | [] |
| 0 | 30 | [] |
| 0 | 31 | [1, 8, 12, 19, 26, 30] |
| 1 | 0 | [3, 5, 7, 9, 11, 14, 15, 16, 17, 18, 23, 25, 26, 27, 28, 29, 30, 31] |
| 1 | 1 | [0, 4, 7, 22] |
| 1 | 2 | [13, 16, 19, 26, 31] |
| 1 | 3 | [2, 6, 24] |
| 1 | 4 | [0, 3, 7, 10, 18, 25] |
| 1 | 5 | [4, 7, 8, 11, 25, 26] |
| 1 | 6 | [5, 9, 12, 27] |
| 1 | 7 | [5, 7, 9, 10, 11, 14, 15, 16, 17, 18, 21, 23, 25, 26, 27, 29, 30, 31] |
| 1 | 8 | [7, 11, 14, 29] |
| 1 | 9 | [1, 19, 26] |
| 1 | 10 | [9, 13, 31] |
| 1 | 11 | [2, 3, 5, 7, 9, 10, 11, 13, 14, 15, 16, 18, 20, 23, 24, 25, 26, 27, 28, 29, 30, 31] |
| 1 | 12 | [7, 11, 25] |
| 1 | 13 | [1, 9, 12, 19, 27] |
| 1 | 14 | [2, 10, 13, 20, 28] |
| 1 | 15 | [3, 14, 21] |
| 1 | 16 | [1, 8, 12, 15, 19, 26, 30] |
| 1 | 17 | [1, 5, 8, 13, 16, 19, 23, 26, 31] |
| 1 | 18 | [3, 5, 6, 7, 9, 11, 14, 15, 16, 18, 23, 24, 25, 26, 27, 28, 29, 30, 31] |
| 1 | 19 | [4, 18, 22, 25] |
| 1 | 20 | [1, 13, 16, 26, 31] |
| 1 | 21 | [6, 20, 24] |
| 1 | 22 | [0, 2, 3, 5, 6, 9, 11, 13, 14, 15, 16, 17, 20, 21, 23, 26, 27, 29, 30, 31] |
| 1 | 23 | [7, 8, 11, 22, 25, 26] |
| 1 | 24 | [1, 8, 9, 12, 19, 23, 26, 27] |
| 1 | 25 | [5, 6, 7, 9, 10, 11, 13, 14, 15, 16, 17, 18, 21, 23, 24, 25, 26, 27, 29, 30] |
| 1 | 26 | [11, 14, 25, 29] |
| 1 | 27 | [1, 8, 19] |
| 1 | 28 | [13, 27, 31] |
| 1 | 29 | [2, 3, 5, 7, 9, 11, 13, 14, 15, 16, 18, 20, 23, 24, 25, 26, 27, 29, 30, 31] |
| 1 | 30 | [7, 25, 29] |
| 1 | 31 | [8, 9, 12, 26, 27] |
| 2 | 0 | [0] |
| 2 | 1 | [1] |
| 2 | 2 | [2] |
| 2 | 3 | [3] |
| 2 | 4 | [4] |
| 2 | 5 | [5] |
| 2 | 6 | [6] |
| 2 | 7 | [7] |
| 2 | 8 | [8] |
| 2 | 9 | [9] |
| 2 | 10 | [10] |
| 2 | 11 | [11] |
| 2 | 12 | [12] |
| 2 | 13 | [13] |
| 2 | 14 | [14] |
| 2 | 15 | [15] |
| 2 | 16 | [16] |
| 2 | 17 | [17] |
| 2 | 18 | [18] |
| 2 | 19 | [19] |
| 2 | 20 | [20] |
| 2 | 21 | [21] |
| 2 | 22 | [22] |
| 2 | 23 | [23] |
| 2 | 24 | [24] |
| 2 | 25 | [25] |
| 2 | 26 | [26] |
| 2 | 27 | [27] |
| 2 | 28 | [28] |
| 2 | 29 | [29] |
| 2 | 30 | [30] |
| 2 | 31 | [31] |
As we can see, each bit in the third input affects the same bit in order in the output. Also, we can notice that only 8 bits in the first input affect the same 6 bits in the output. But for the second input, each bit is affecting several bits. Although we can write a closed-form logic expression for this, we would write a code instead.
The following code implements a C++ function that can use three generated numbers (at specific locations) to generate the next number:
uint inp_out_xor_bitsY[32] = {
0xfe87caa8,
0x400091,
0x84092000,
0x1000044,
0x2040489,
0x6000990,
0x8001220,
0xeea7cea0,
0x20004880,
0x4080002,
0x80002200,
0xff95eeac,
0x2000880,
0x8081202,
0x10102404,
0x204008,
0x44089102,
0x84892122,
0xff85cae8,
0x2440010,
0x84012002,
0x1100040,
0xecb3ea6d,
0x6400980,
0xc881302,
0x6fa7eee0,
0x22004800,
0x80102,
0x88002000,
0xef95eaac,
0x22000080,
0xc001300
};
uint gen_new_number(uint MT_624, uint MT_623, uint MT_227) {
uint r = 0;
uint i = 0;
do {
r ^= (MT_623 1) * inp_out_xor_bitsY[i++];
}
while (MT_623 >>= 1);
MT_624 = 0x89130204;
MT_624 ^= MT_624 >> 16;
MT_624 ^= MT_624 >> 8;
MT_624 ^= MT_624 >> 4;
MT_624 ^= MT_624 >> 2;
MT_624 ^= MT_624 >> 1;
r ^= (MT_624 1) * 0x44081102;
r ^= MT_227;
return r;
}We have tested this code by using the standard MT library in C to generate the sequence of the random numbers and match the generated numbers from the function with the next generated number from the library. The output was 100% matching for several millions of generated numbers with different seeds.
3.2.4.3 Further Improvement
We have seen in the previous section that we can use three generated numbers to generate the new number in the sequence. But we noticed that we only need 8 bits from the first number, which we XOR, and if the result of the XORing of them is one, we XOR the result with a constant, 0x44081102. Based on this observation, we can instead ignore the first number altogether and generate two possible output values, with or without XORing the result with 0x44081102. Here is the code segment for the new function.
#include
using namespace std;
uint inp_out_xor_bitsY[32] = {
0xfe87caa8,
0x400091,
0x84092000,
0x1000044,
0x2040489,
0x6000990,
0x8001220,
0xeea7cea0,
0x20004880,
0x4080002,
0x80002200,
0xff95eeac,
0x2000880,
0x8081202,
0x10102404,
0x204008,
0x44089102,
0x84892122,
0xff85cae8,
0x2440010,
0x84012002,
0x1100040,
0xecb3ea6d,
0x6400980,
0xc881302,
0x6fa7eee0,
0x22004800,
0x80102,
0x88002000,
0xef95eaac,
0x22000080,
0xc001300
};
tuple gen_new_number(uint MT_623, uint MT_227) {
uint r = 0;
uint i = 0;
do {
r ^= (MT_623 1) * inp_out_xor_bitsY[i++];
}
while (MT_623 >>= 1);
r ^= MT_227;
return make_tuple(r, r^0x44081102);
} 4. Improving MT algorithm
We have shown in the previous sections how to use ML to crack the MT algorithm and use only two or three numbers to predict the following number in the sequence. In this section, we will discuss two issues with the MT algorithm and how to improve them. Studying those issues can be particularly useful when MT is used as a part of cryptographically-secure PRNG, like in CryptMT. CryptMT uses Mersenne Twister internally, and it was developed by Matsumoto, Nishimura, Mariko Hagita, and Mutsuo Saito [2].
4.1 Normalizing the Runtime
As we described in Section 2, MT consist of two steps, twisting and tempering. Although the tempering step is applied on each step, the twisting step is only used when we exhaust all the states, and we need to twist the state array to create a new internal state. That is OK, algorithmically, but from the cybersecurity point of view, this is problematic. It makes the algorithm vulnerable to a different type of attack, namely a timing side-channel attack. In this attack, the attacker can determine when the state is being twisted by monitoring the runtime of each generated number, and when it is much longer, the start of the new state can be guessed. The following figure shows an example of the runtime for the first 10,000 generated numbers using MT:
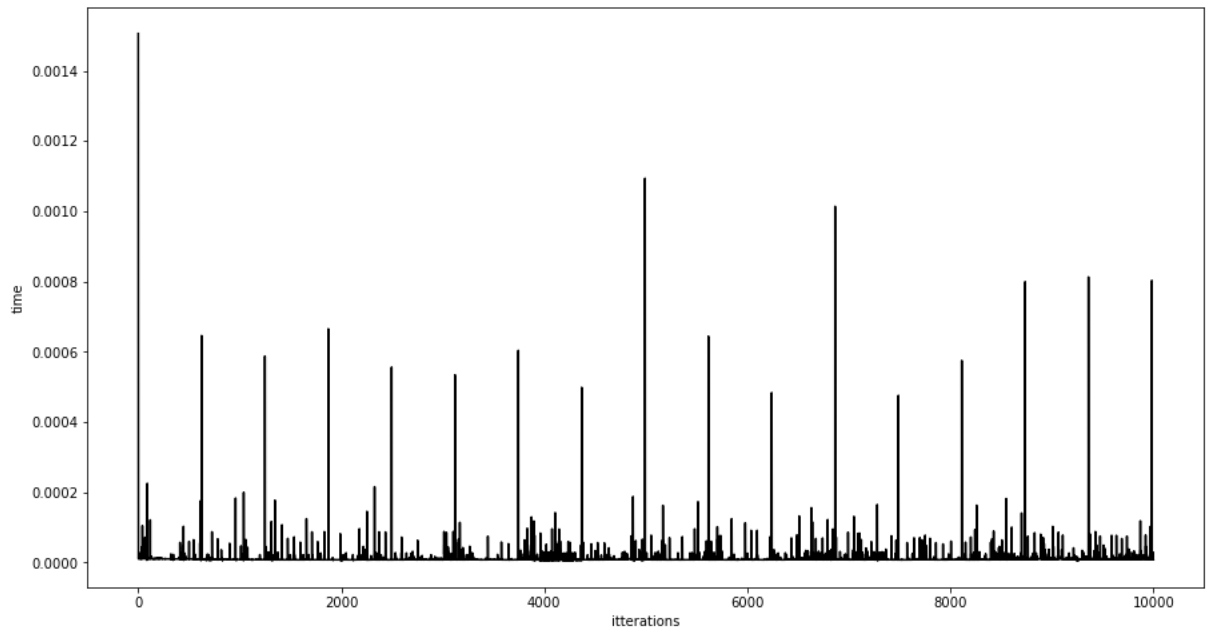
We can clearly see that every 624 iterations, the runtime of the MT algorithm increases significantly due to the state-twisting evaluation. Hence, the attacker can easily determine the start of the state twisting by setting a threshold of 0.4 ms of the generated numbers. Fortunately, this issue can be resolved by updating the internal state every time we generate a new number using the progressive formula we have created earlier. Using this approach, we have updated the code for MT and measured the runtime again, and here is the result:
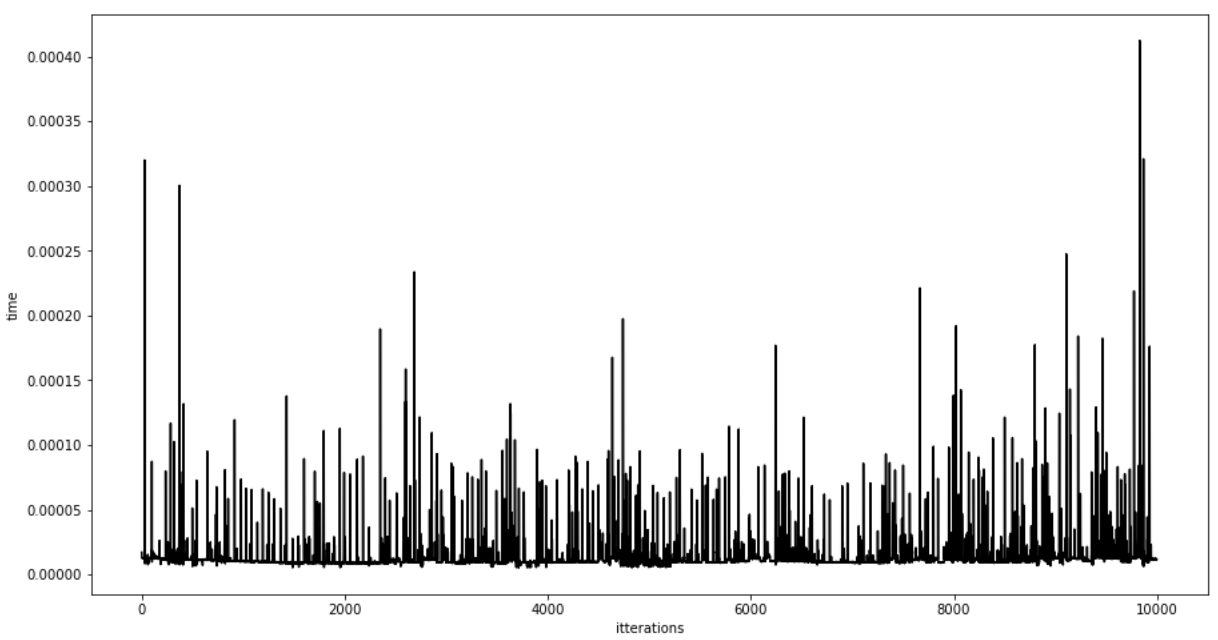
We can see that the runtime of the algorithm is now normalized across all iterations. Of course, we checked the output of both MT implementations, and they got the exact sequences. Also, when we evaluated the mean of the runtime of both MT implementations over millions of numbers generated, the new approach is a little more efficient but has a much smaller standard deviation.
4.2 Changing the Internal State as a Whole
We showed in the previous section that the MT twist step is equivalent to changing the internal state progressively. This is the main reason we were able to build a machine learning that can correlate a generated output from MT to three previous outputs. In this section, we suggest changing the algorithm slightly to overcome this weakness. The idea is to apply the twisting step on the old state at once and generate the new state from it. This can be achieved by doing the twist step in a new state array and swap the new state with the old one after twisting all the states. This will make the state prediction more complex as different states will use different distances for evaluating the new state. For example, all the new states from 0 to 226 will use the old states from 397 to 623, which are 397 apart. And all the new states from 227 to 623 will be using the value of the old states from 0 to 396, which are 227 apart. This slight change will generate a more resilient PRNG for the above-suggested attack, as any generated output can be either 227 or 397 away from the output it depends on as we don’t know the position of the generated number (whether it is in the first 227 numbers from the state or in the last 397 ones). Although this will generate a different sequence, the new state’s prediction from the old ones will be harder. Of course, this suggestion needs to be reviewed more deeply to check the other properties of the outcome PRNG, such as periodicity.
5. Conclusion
In this series of posts, we have shared the methodology of cracking two of the well-known (non-cryptographic) Pseudo-Random Number Generators, namely xorshift128 and Mersenne Twister. In the first post, we showed how we could use a simple machine learning model to learn the internal pattern in the sequence of the generated numbers. In this post, we extended this work by applying ML techniques to a more complex PRNG. We also showed how to split the problem into two simpler problems, and we trained two different NN models to tackle each problem separately. Then we used the two models together to predict the next sequence number in the sequence using three generated numbers. Also, we have shown how to deep dive into the models and understand how they work internally and how to use them to create a closed-form code that can break the Mersenne Twister (MT) PRNG. At last, we shared two possible techniques to improve the MT algorithm security-wise as a means of thinking through the algorithmic improvements that can be made based on patterns identified by deep learning (while still recognizing that these changes do not themselves constitute sufficient security improvements for MT to be itself used where cryptographic randomness is required).
The python code for training and testing the model outlined in this post is shared in this repo in a form of a Jupyter notebook. Please note that this code is based on top of an old version of the code shared in the post [3] and the changes that are done in part 1 of this post.
Acknowledgment
I would like to thank my colleagues in NCC Group for their help and support and for giving valuable feedback the especially in the crypto/cybersecurity parts. Here are a few names that I would like to thank explicitly: Ollie Whitehouse, Jennifer Fernick, Chris Anley, Thomas Pornin, Eric Schorn, and Eli Sohl.
References
[1] Mike Shema, Chapter 7 – Leveraging Platform Weaknesses, Hacking Web Apps, Syngress, 2012, Pages 209-238, ISBN 9781597499514, https://doi.org/10.1016/B978-1-59-749951-4.00007-2.
[2] Matsumoto, Makoto; Nishimura, Takuji; Hagita, Mariko; Saito, Mutsuo (2005). “Cryptographic Mersenne Twister and Fubuki Stream/Block Cipher” (PDF).
[3] Everyone Talks About Insecure Randomness, But Nobody Does Anything About It
