In the following blog post, we explore how overfitting can affect Large Language Models (LLMs) in particular, since this technology is used in the most promising AI technologies we see today (chatGPT, LLaMa, Bard, etc). Furthermore, by exploring the likelihood of inferring data from the dataset, we will determine how much we can trust these kind of models to not reproduce copyrighted content that existed in their training dataset, which is another risk associated with overfitting.
Overfitting is a concept used in the ML field that refers to the situation where the model fits the training data so well that it cannot generalise its predictions for unseen data. Although this may not be the perfect explanation for a data scientist, we could say that a model with good generalisation is “understanding” a problem. In contrast, an overfitted model is “memorising” the training dataset. In the real world, data scientists try to find a balance where the model generalises well enough, even if some overfitting exists.
As we have seen in most ML models, overfitting can be abused to perform certain attacks such as Membership Inference Attacks (MIAs), among other risks. In MIAs, attackers infer if a piece of data belongs to the training dataset by observing the predictions generated by the model. So, for example, in an image classification problem, a picture of a cat that was used in the training process will be predicted as “cat” with a higher probability than other pictures of cats that were not used in the training process, because that small degree of overfitting that most models have.
Overfitting in LLMs
Most of the LLMs we see today predict a new token (usually a small piece of a word) based on a given sequence of tokens (typically, an input text). Under the hood, the model generates a probability for each one of the tokens that could be generated (the “vocabulary” of the model). As an example, the design of Databricks’ Dolly2 model, as it is implemented in HuggingFace, is following:
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50280, 2560)
(layers): ModuleList(
(0-31): 32 x GPTNeoXLayer(
(input_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(attention): GPTNeoXAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): Linear(in_features=2560, out_features=7680, bias=True)
(dense): Linear(in_features=2560, out_features=2560, bias=True)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=2560, out_features=10240, bias=True)
(dense_4h_to_h): Linear(in_features=10240, out_features=2560, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=2560, out_features=50280, bias=False)
)
The “out_features” are 50280 probabilities/scores, one for each possible token from the vocabulary. Based on the training dataset this model was exposed to, they show the likelihood of the next token to be predicted. Then, one of the tokens with the highest score is chosen, based on parameters such as “temperature” or “Top P”, which is generally shown as the next generated token.
However, models also allow you to inspect those scores, with independence of the chosen token. For example, the code snippet below shows how the HuggingFace model “databricks/dolly-v2-3b” was parametrized to show the complete score information.
prompt_text = "Do or do"
inputs = tokenizer(prompt_text, return_tensors="pt")
input_ids = inputs["input_ids"]
x = model.generate(
input_ids=input_ids.to(model.device),
attention_mask = torch.ones(input_ids.size(0), input_ids.size(1)),
pad_token_id=tokenizer.eos_token_id,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=1
)
next_id = x.sequences[0][-1]
print_top_scores(prompt_text, x.scores, next_id)
Although the implementation of “print_top_scores()” is not shown for clarity, it shows the top 10 candidates for the next token with their corresponding normalised scores:
Do or do not (0.9855502843856812)
Do or do- (0.0074768210761249)
Do or do NOT (0.0016151140443980)
Do or do N (0.0005388919962570)
Do or do_ (0.0003805902961175)
Do or do or (0.0003312885237392)
Do or do you (0.0003257314674556)
Do or do Not (0.0002487517194822)
Do or do ( (0.0002326328831259)
Do or do \n (0.0002092608920065)Based on this information, “ not” (yes, beginning with whitespace) seems to have the highest score and, if we continue generating tokens, we obtain the following text.
| Input | Top 3 Probs (Dolly2) |
| Do or do not | Do or do not, (0.30009099) Do or do not do (0.17540030) Do or do not. (0.13311417) |
| Do or do not, | Do or do not, but (0.25922420) Do or do not, there (0.23855654) Do or do not, the (0.07641381) |
| Do or do not, there | Do or do not, there is (0.99556446) Do or do not, there’s (0.00221653) Do or do not, there are (0.00051577) |
| Do or do not, there is | Do or do not, there is no (0.97057723) Do or do not, there is a (0.01224006) Do or do not, there is more (0.00181120) |
| Do or do not, there is no | Do or do not, there is no try (0.74742728) Do or do not, there is no ‘ (0.09734915) Do or do not, there is no ” (0.08001318) |
The “Do or do not, there is no try”, obviously part of the training dataset as a mythic Star Wars quote, was generated from the “Do or do” input text. Have you seen where we cheated? Certainly, “Do or do not, but” had a slightly higher score than “Do or do not, there”, but they were very similar. That happened because both sentences (or pieces of sentences) probably belonged to the training dataset. We will talk more about this later.
Will that happen with every single LLM or just Dolly2? Let’s see an example using the “gpt2” model, also hosted in Huggingface.
Do or do not do. (0.0317150019109249)
Do or do not you (0.0290195103734731)
Do or do not use (0.0278038661926984)
Do or do not have (0.0234157051891088)
Do or do not. (0.0197649933397769)
Do or do not take (0.0186729021370410)
Do or do not get (0.0179356448352336)
Do or do not buy (0.0150753539055585)
Do or do not make (0.0147862508893013)
Do or do not, (0.0139999818056821)As you can see, it is much more challenging to detect which of the next token candidates corresponds to the training dataset. Although they (in red) are still in the top 10 of the highest scores, they are not even in the top 3.
We find the complete opposite situation with OpenAI’s Playground, model “text-davinvi-003” (GPT-3) and temperature equal to zero (always choose the more probable next token).
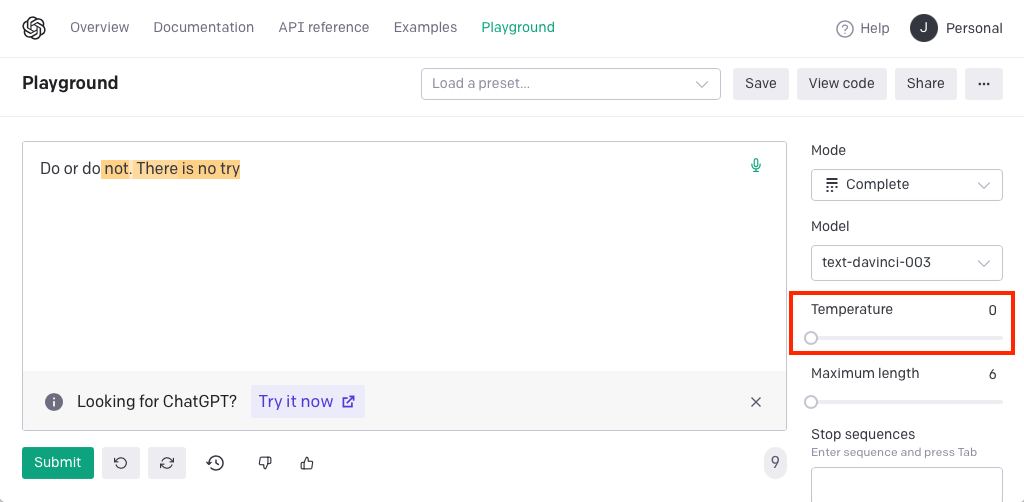
“text-davinci-003” generating overfitted text
We can see how the target sentence was generated. Although the Playground supports providing the detailed probabilities for each token, it was not necessary at this time, since we found that the tokens for the target text were always the candidates with the highest scores.
This is just an example, not a complete and detailed analysis, but it illustrates perfectly how overfitting usually impacts more on bigger models: As a reference, this is the size of the above mentioned models in billions of parameters: GPT-3 (175b), Dolly2 (3b) and GPT-2 (1.5b).
Membership Inference
As shown above, detecting which token may correspond to overfitted data is not always easy, so we tried several additional experiments to find an effective way to exploit Membership Inference Attacks (MIA) in LLMs. Although we tried other methods, the technique used in the Beam Search generation strategy was also the most effective for MIAs. This technique calculates a probability of a sequence of tokens as a product of each token’s probability. As new tokens are generated, the N highest probability sequences are kept. Let’s see an example with our target quote: “Do or do not, there is no try”.
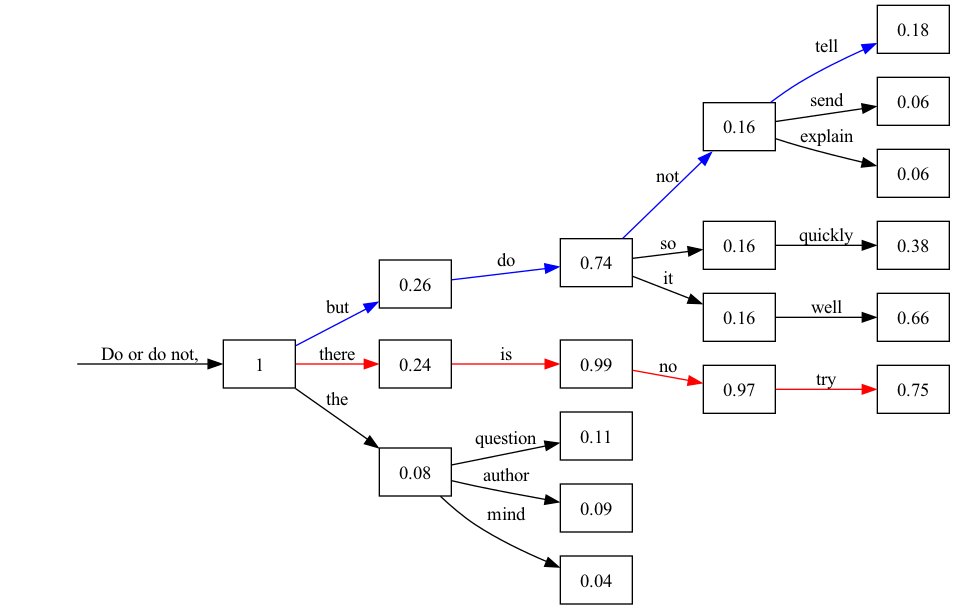
Beam Search Tree
The graph above shows candidate tokens and their probability for each step. Some nodes with very low probabilities have not been represented to facilitate analysis, but remember that the top 3 scores for each next candidate token were generated.
The path in blue represents the “Greedy Search” result, which means always choosing the more probable candidate token on every step (in the absence of “temperature”). The sentence “Do or do not, but do not tell” is generated in our example. However, you can easily see that the path in red (“Do or do not, there is no try”) has higher probabilities in all the sequence, except in the first element. If we calculate the overall probability for the red path, it will be 0.17, much higher than the blue path, which is 0.01. This happens because, although there were other potential tokens with high probability at some point, an overfitted sentence should have high probabilities (not necessarily the highest, but consistently high ones) for every single token.
As this technique is already implemented in LLMs to generate more natural text, we can easily obtain a list of the most probable sequences using this approach. For example, in the following code snippet, we generate tokens using a beam size of 10 (we keep the sequences of the 10 highest probabilities) and obtain all of them after the last step.
x = model.generate(
input_ids=input_ids.to(model.device),
attention_mask = torch.ones(input_ids.size(0), input_ids.size(1)),
pad_token_id=tokenizer.eos_token_id,
num_beams=10,
num_return_sequences=10,
early_stopping=True,
max_new_tokens=6
)
We can add a little bit more code to calculate the final probability, since that is not given by default, and we will obtain the following results:
Do or do not, there is no try (0.050955554860769010)
Do or do not; there is no try (0.025580763711396462)
Do or do not, there is no ' (0.006636739833931039)
Do or do not, but do it well (0.005970277809022071)
Do or do not, there is no " (0.005454866792928952)
Do or do not; there is no " (0.005357746163965427)
Do or do not, but do or do (0.005282247360819922)
Do or do not; there is no ' (0.004159457944373084)
Do or do not, but do so quickly (0.003438846991493329)
Do or do not, but do not tell (0.001629174555881396)
The two results with higher probabilities are the same sentence, with some minor variations, which makes sense given that it is a transcription of a movie and could have been written differently.
Unfortunately, this technique still doesn’t work to exploit MIAs in smaller language models such as GPT-2.
It is worth mentioning that datasets used to train base models are typically built by collecting public text data from the Internet, so the impact of exploiting an MIA is low. However, the impact increases if the base model is fine-tuned using a private and sensitive dataset that should not be exposed.
Copyrighted Material
Another side effect of overfitting in generative models is that they can generate copyrighted material. As happened before, in theory, the bigger a model is, the more likely this may happen.
In the screenshot below, we see OpenAI’s Playground (“temperature” set to 0) reproducing the beginning of the well-known novel “The Lord of the Rings” after several words matching that beginning.

“text-davinci-003” generating copyrighted text
As can be observed in the probabilities of each token (2 examples are shown), the likelihood of generating copyrighted material increases after each new token is generated. After a few tokens are generated, the following tokens follow the target sequence with probabilities higher than 90-95%, so it is likely reproducing copyrighted material. However, the likelihood of the model generating copyrighted material from scratch is much lower.
Conclusions and Recommendations
Overfitting is definitely a risk also in LLMs, especially in larger models. However, its impact strongly depends on the model’s purpose. For example, producing copyrighted material or leaking information from the training dataset may be security problems, depending on how the model is used.
Models trained with sensitive material should avoid providing verbose information such as the list of candidate next tokens and their probabilities. This information is helpful for debugging, but it facilitates MIAs. Also, deploy rate limiting controls, since exploiting this kind of attack requires massive generation requests. Finally, if possible, don’t let users set parameters other than the input text.
For models generating output that may be used as original content, it is recommended to keep high “temperature” and low “num_beams” (“best of” in OpenAI’s Playground). Also, models can be fine-tuned to cite the original author when reproducing copyrighted material, as chatGPT does. Other heuristic controls may also be deployed to guarantee that no copyrighted material is produced.
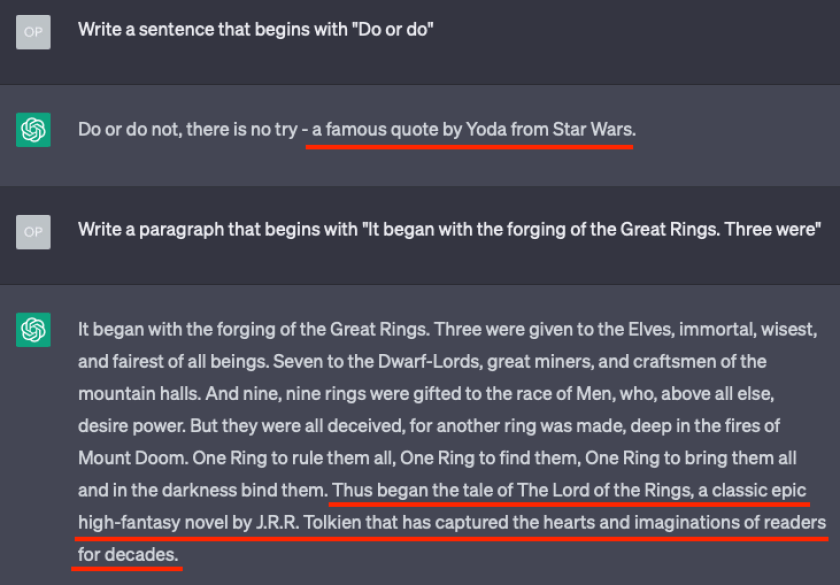
chatGPT citing copyrighted text
Acknowledgements
Special thanks to Chris Anley, Eric Schorn and the rest of the NCC Group team that proofread this blogpost before being published.
