This is the second blog post in a new code-centric series about selected optimizations found in pairing-based cryptography. Pairing operations are foundational to the BLS Signatures central to Ethereum 2.0, the zero-knowledge arguments underpinning Filecoin, and a wide variety of other emerging applications.
While my prior blog series, “Pairing over BLS12-381,” implemented the entire pairing operation from start to finish in roughly 200 lines of high-level Haskell, this current blog series, “Optimizing Pairing-Based Cryptography” looks at lower-level performance optimizations in more operational systems. The first post in this series covered modular Montgomery arithmetic in Rust from start to finish. This second post takes the Montgomery multiplication algorithm developed in Rust even further to seek the maximum performance a modern x86-64 machine can deliver from an implementation hand-written in assembly language. Several specialized instructions and advanced micro-architectural features enabling increased parallelism result in a Montgomery multiplication routine running more than 15X faster than a generic Big Integer implementation.
Overview
Pairing-based cryptography is fascinating because it utilizes such a wide variety of concepts, algorithms, techniques and optimizations. For reference, the big picture on pairing can be reviewed in the prior series of blog posts listed below.
• Pairing over BLS12-381, Part 1: Fields
• Pairing over BLS12-381, Part 2: Curves
• Pairing over BLS12-381, Part 3: Pairing!
This current blog post focuses on optimizing the most expensive of basic field arithmetic operations: modular multiplication. First, a reference function implemented in Rust with the BigUint library crate is presented alongside a similar reference function adapted for use with Montgomery-form operands. Second, a more optimized routine utilizing operands constructed solely from 64-bit unsigned integers and developed in the prior blog post is presented – this serves as the jumping-off point for assembly language optimization. Third, the complete assembly routine is developed and described with interspersed insights on CPU architecture, micro-architecture, and register allocation. This post then wraps up with some figure of-merit benchmarking results that compare the various implementations.
All of the code is available, ready-to-run and ready-to-modify for your own experimentation. The code is nicely self-contained and understandable, with zero functional dependencies and minimal test/build complexity. On Ubuntu 20.04 with Rust, git and clang preinstalled, it is as simple as:
$ git clone https://github.com/nccgroup/pairing.git $ cd pairing/mont2 $ RUSTFLAGS="--emit asm -C target-cpu=native" cargo bench
The Reference Operations
Rust, along with the BigUint library crate, makes the basic modular multiplication operation exceptionally easy to code. The excerpt below defines the BLS12-381 prime field modulus with the lazy_static macro and then proceeds to implement the modular multiplication function mul_biguint() using that fixed modulus. This reference function corresponds to the modular multiplication performance a generic application might achieve, and is used later as the benchmark baseline. [Code excerpt on GitHub]
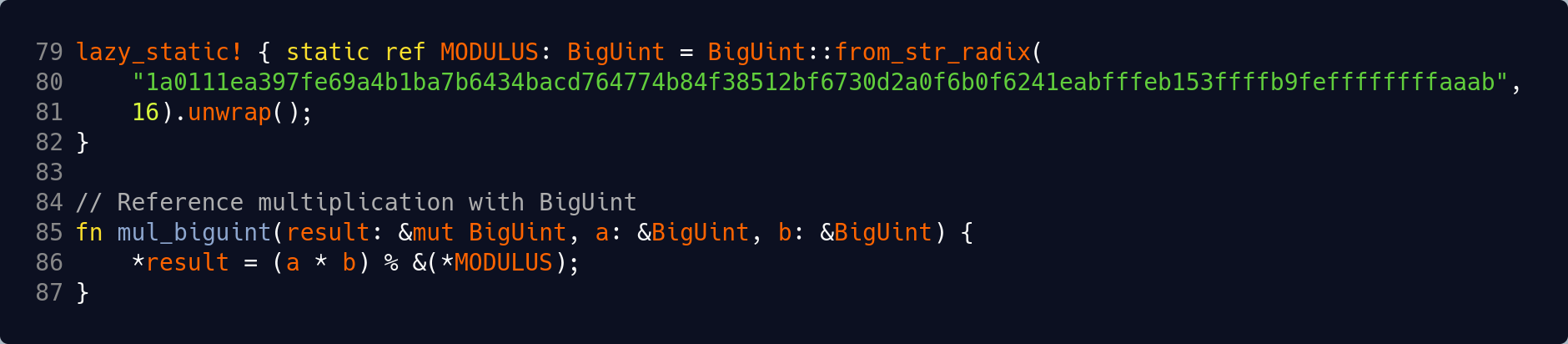
As described in the prior blog post, the Montgomery multiplication algorithm has a lot more potential for performance optimization but uses operands in the Montgomery form ã = a · R mod N, where a is the normal value (or normal form), N is the MODULUS and R is 2384 in our scenario. When operands in Montgomery form are multiplied together, an instance of R−1 needs to be factored into the calculation in order to maintain the result in correct Montgomery form. Thus, the actual operation is mont_mul(ã, b̃) = ã · b̃ · R−1 mod N. The code below declares the R−1 = R_INV constant as calculated in the prior blog post, utilizes the same MODULUS constant declared above, and so implements our mont_mul_biguint() Montgomery multiplication reference function. [Code excerpt on GitHub]
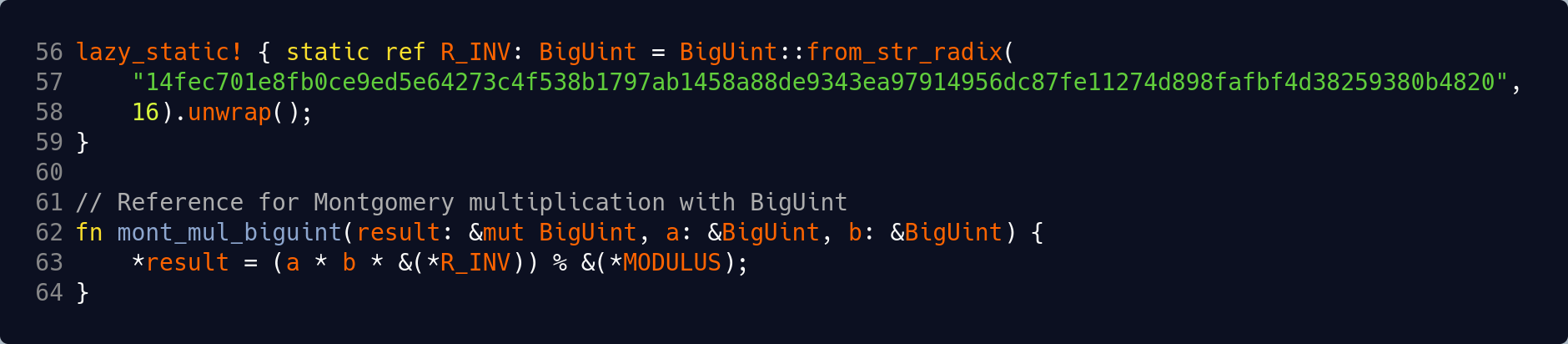
Note that the above function currently has even worse performance characteristics than the prior baseline. This is due to the additional multiplication involving R_INV delivering an even larger input to the very expensive modular reduction operator which involves a division operation. However, it can serve as a more formalized definition of correct functionality, so it will be used internally to support the test code which compares actual versus expected results across different implementations. As an aside, recall that the extra expense of converting the operands to/from Montgomery form is expected to be amortized across many (hopefully now much faster) interim operations.
Montgomery Multiplication Using Rust’s Built-In Types
The primary issue with each of the above multiplication routines is the expensive division lurking underneath the modulo operator. The BigUint crate is wonderful in that it supports both arbitrary precision operands and moduli. However, this flexibility precludes some of the aggressive performance optimizations that can be implemented with fixed-size operands and a constant modulus.
The Rust code shown below from the prior blog post introduces the fixed data structure used for the operands. Operands consist of an array of six 64-bit unsigned integers, each known as a limb. This is followed by the ‘magic constant’ N_PRIME derived in the prior blog post for use in the reduction step, and then the complete Montgomery multiplication function using only Rust’s built-in operators and data types. [Code excerpt on GitHub]
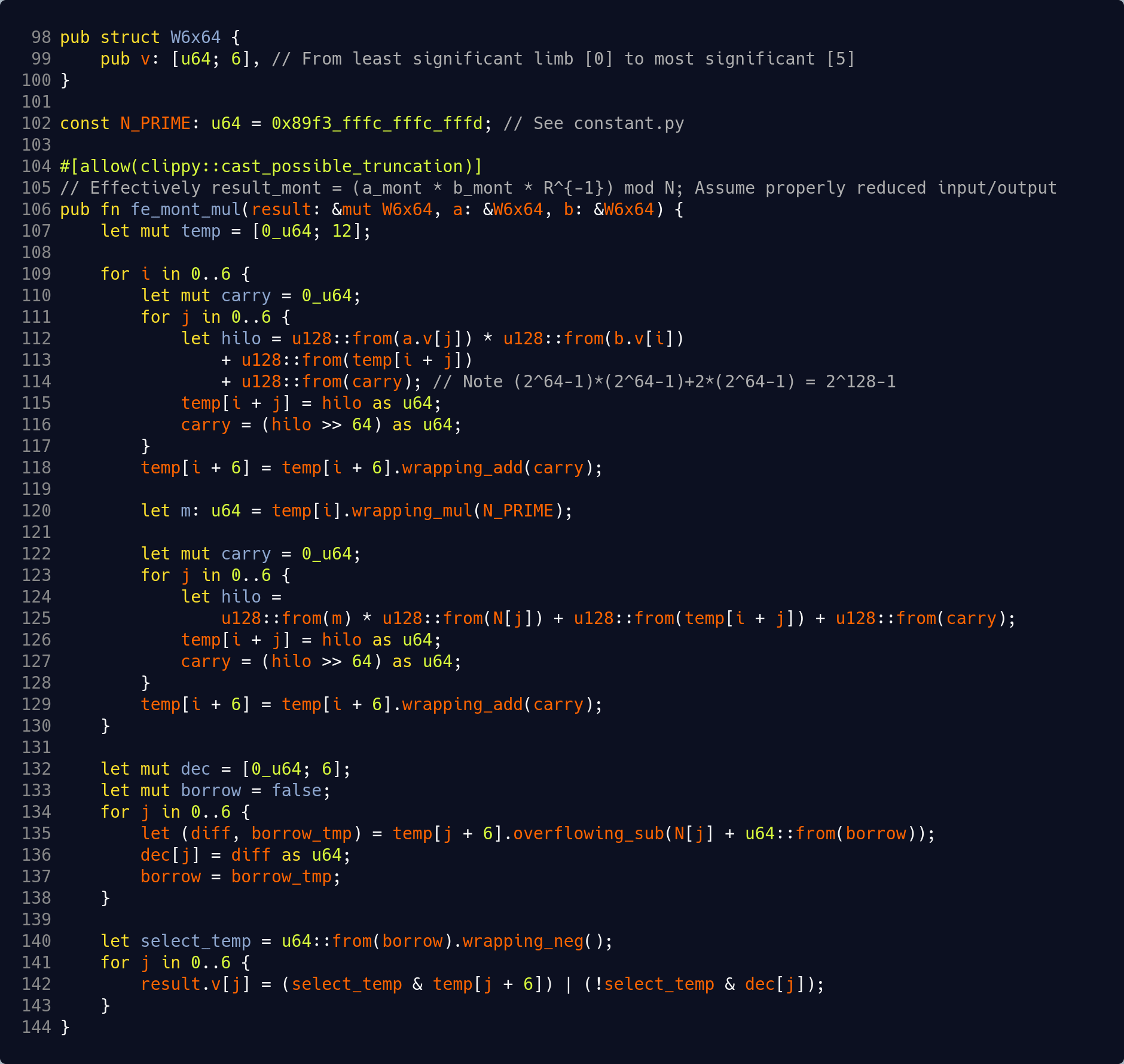
There are three interesting and related things to observe in the code above.
- A temp array is declared on line 107 that is capable of holding twelve 64-bit limbs. Intuitively, that size makes sense since the overall operation involves a multiplication of two operands, where each operand consists of six 64-bit limbs, so a ‘double-width’ intermediate result is appropriate.
- The outer loop wraps a partial product step in the first inner loop followed by a reduction step in the second inner loop, and the outer loop index i always acts as a base address whenever the temp array is accessed. Looking more closely at the logic executed during each outer loop iteration, only seven limbs of the temp array are ever active, which is a noticeably smaller working set relative to the overall size of twelve in the temp declaration.
- As the outer loop iterates, the code essentially steps forward through the working set of the temp array from least significant toward most significant limb, never going fully backwards. In fact, incrementing the loop index i and using it as a base address means the least significant values are effectively falling away one at a time; the final result is derived from only the most significant six limbs of the temp array.
These three observations suggest that it is possible to elegantly implement the work done inside the outer loop within only a handful of active registers. The outer loop can then either iterate as shown or be unrolled, while it shifts the working set one step forward through the temp array each time.
An Aside: CPU Architecture, Micro-architecture, and Register Allocation
Some basic foundation needs to be built prior to jumping into the assembly language implementation. While the term ‘CPU Architecture’ does not have a single, simple or perfectly agreed-upon definition, in this context it describes the higher-level software instruction set and programming model of a processor system – the programmer’s view. At a lower level, the term ‘CPU Micro-architecture’ then describes how a specific processor implementation is logically organized to execute that instruction set – these underlying mechanisms are largely hidden from the application programmer. Both areas have seen tremendous progress and greater complexity over time in the never ending quest for performance that largely comes from increased parallelism. There are a few things to observe for each topic, starting from the lower-level and working upwards.
CPU Micro-architecture
A view into the micro-architecture of Intel’s Core2 machine is shown below. While that machine is over a decade old, the diagram remains very instructive and more modern versions have similar structure with greatly increased capacities. The assembly code we soon develop should run well on all modern Intel and AMD x86-64 processors shipped within the past 5 years (at least).
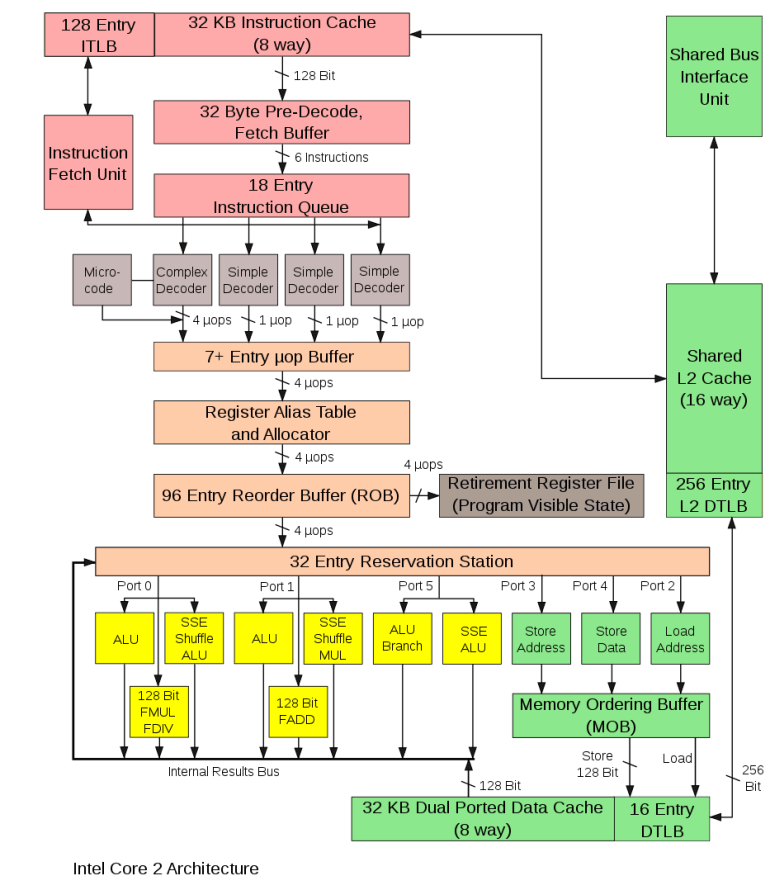
There are four interesting things to observe in the diagram above.
- The (pink) instruction fetch logic is capable of supplying six instructions from the fetch buffer to the instruction queue per cycle. Clearly the intent is to keep the multiple parallel execution units downstream (described next) stuffed full of work.
- The (yellow) execution units are capable of executing multiple similar and dissimilar operations in parallel. The configuration is intended to support many simple and frequent operations separately from the fewer, more complex and rarer operations. The various operations will clearly involve very different throughput and latency characteristics.
- The (salmon) reservation station helps manage the operand dependencies between instructions, and the register alias table allows for more physical registers than logical registers. The adjacent reorder buffer and retirement register file logic allows instructions to execute out-of-order but get committed in-order. While humans typically think in a nice orderly step-by-step fashion, the actual instruction execution patterns can go wildly out-of-order (provided they are ultimately finalized in-order).
- While the specific individual pipeline stages are not shown, modern processors have very deep pipelines and thus require extensive branch prediction logic to minimize overhead from mispredictions. This is pertinent to unrolling small loops.
The four items above allow the processor to extract a large amount of the underlying instruction-level parallelism throughout each of the fetch, decode, execute and finalize/retire steps. It is quite fantastic that all of this complexity is effectively hidden from the application programmer. A bigger, better and newer micro-architecture should simply result in better performance on strictly unchanged code.
CPU Architecture
In some cases, specialized instructions are added to the programming model that provide significant speed-up for very specific algorithms. While many people first think of the very well-known ‘Intel MMX instructions for multimedia algorithms’, there have been many other less prominent instances over the years. Intel’s ADX (Multi-Precision Add-Carry Instruction Extensions) feature provides two new addition instructions that can help increase the performance of arbitrary precision arithmetic. Intel’s BMI2 (Bit Manipulation Instruction Set 2) feature contains a new flag-friendly multiplication instruction among several others not relevant to our purpose. Processors supporting these feature extensions have been shipping since roughly 2015, and may offer a significant performance benefit.
The ‘native’ Montgomery multiplication Rust code last shown above involved a large amount of addition operations (outside of the array index calculation) centered around lines 112-114, 118, 124-125 and 129. These operations are building larger-precision results (e.g., a full partial product) from smaller-precision instructions (e.g., a 64-bit add). Normally, a series of ‘Add with carry’ (ADC) instructions are used that add two operands and the carry(in) flag to produce a sum and a new carry(out) flag. The instructions are ordered to work on the least-to-most significant operand limb one at a time. The dependence upon a single carry flag presents a bottleneck that allows just one chain to operate at a time in principle, thus limiting parallelism.
Intel realized the limitation of a single carry flag, and introduced two instructions that effectively use different carry flags. This allows the programmer to express more instruction-level parallelism by describing two chains that can be operating at the same time. The ADX instruction extensions provide:
- ADCX Adds two 64-bit unsigned integer operands plus the carry flag and produces a 64-bit unsigned integer result with the carry out value set in the carry flag. This does not affect any other flags (as the prior ADD instructions did).
- ADOX Adds two 64-bit unsigned integer operands plus the overflow flag and produces a 64-bit unsigned integer result with the carry out value set in the overflow flag. This does not affect any other flags. Note that ordinarily the overflow flag is used with signed arithmetic.
Meanwhile, the Rust code also contains a significant amount of multiplication operations interspersed amongst the addition operations noted above. The ordinary MUL instruction multiplies two 64-bit unsigned integer operands to produce a 128-bit result placed into two destination registers. However, this result also affects the carry and overflow flags – meaning it will interfere with our ADCX and ADOX carry chains. Furthermore, the output registers must be %rax and %rdx which limits flexibility and constrains register allocation. To address this, the BMI2 instruction extensions include:
- MULX Multiplies two 64-bit unsigned integer operands and produces an unsigned 128-bit integer result stored into two destination registers. The flags are not read nor written, thus enabling the interleaving of add-with-carry operations and multiplications.
The two new addition instructions inherently overwrite one of the source registers with the destination result. In other words, adcxq %rax, %r10 will add %rax to %r10 with the carry flag, and place the result into %r10 and the carry flag. The new multiplication instruction requires one of its source operands to always be in %rdx. In other words, mulxq %rsi, %rax, %rbx is the multiplication of %rsi by %rdx with the lower half of the result written into %rax and the upper half written into %rbx. The q suffix on each instruction is simply the quadword suffix syntax of the GNU Assembler.
Register Allocation
The three new instructions described above will form the core of the Montgomery multiplication function in assembly. Since the x86 instruction set is rather register constrained, a strategy that minimizes the actual working set of active values must be developed. We saw earlier how only seven limbs of temp are in play at any one time and the outer loop index i formed a base address when accessing temp. Consider a ‘middle’ iteration of the outer loop, as the simpler first iteration can be derived from this. This flattened iteration is implemented as an assembler macro that can be later placed singly inside an outer loop or in multiple back-to-back instances that unroll the outer loop.
The first inner loop calculating the partial product will be unrolled and assumes temp[i + 0..6] (exclusive) arrives in registers %r10 through %r15. The %rax and %rbx registers will temporarily hold multiplication results as we step through a.v[0..6] * b.v[i] (with a fixed i). The a.v[0..6] (exclusive) operands will involve a relative address using %rsi as the base, while the fixed operand will be held in %rdx. At the end of the inner loop, the %rbp register will be used to hold temp[i + 6].
The second inner loop implementing the reduction step will also be unrolled and assumes temp[i + 0..7] (exclusive) is provided in the registers %r10 through %r15 along with %rbp. The register strategy for holding the multiplication results is modified slightly here due to A) the add instruction requiring a source operand being overwritten by the result, and B) the calculation process effectively shifts the working set to the right by one step (thus the least significant value will drop away, but its carry out will still propagate).
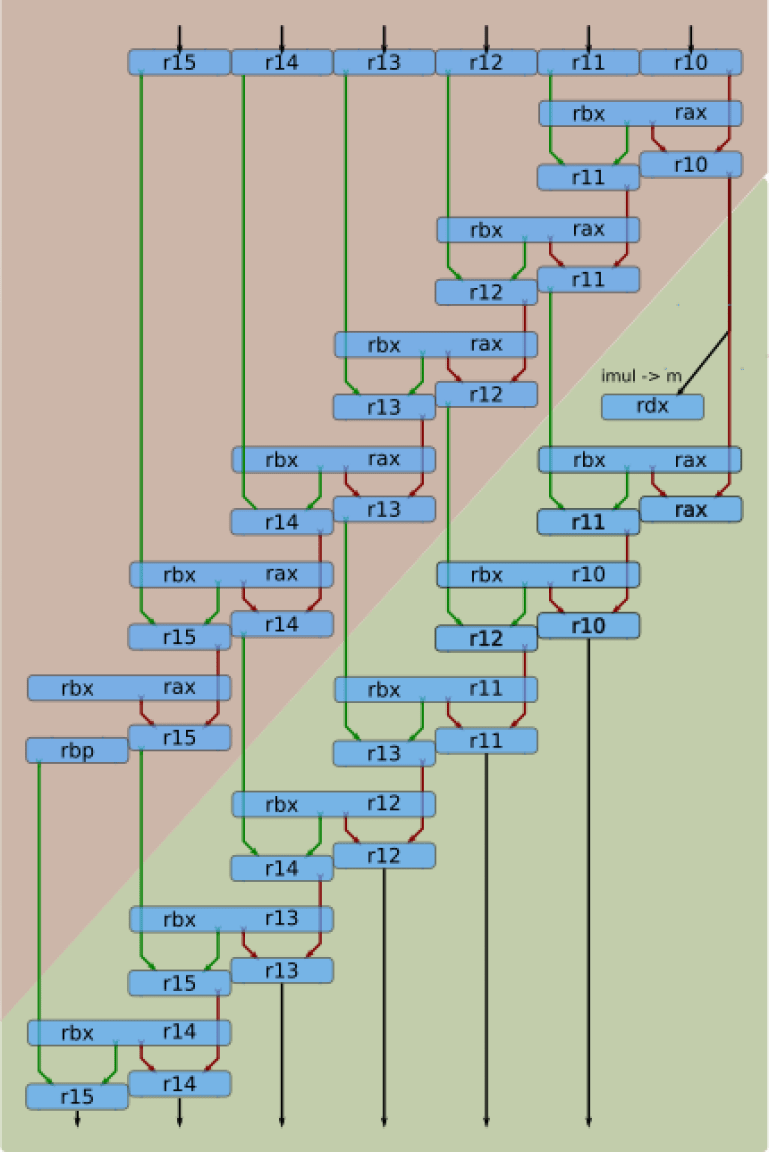
The general plan for register allocation within one ‘middle’ iteration of the outer loop is shown above in simplified fashion. The upper crimson triangle implements the partial product inner loop and is executed first. The lower green triangle implements the reduction step and executes second. Double-width boxes hold the multiplication results, and the red/green arrows identify the two separate carry chains of the addition instructions. The nearly side-by-side placement of the addition operations is meant to hint at their parallel operation. While things visually appear to step forward in a nice orderly single-cycle progression, multiplication latencies are significantly higher than addition so the out-of-order capabilities of the micro-architecture is crucial to performance. The output data within %r10 through %r15 is compatible with input data within %r10 through %r15, so instances of this block can be repeated one after another.
The initial iteration of the outer loop is a simplification of that shown above. Simply assume %r10 through %r15 start at zero and remove everything no longer needed.
Montgomery Multiplication in Assembly
The bulk of the hard work has now been done. A macro implementing one iteration of the outer loop in x86-64 assembly is shown below. The fully unrolled outer loop is implemented with a simplified initial instance followed by five back-to-back instantiations of this code. [Code excerpt on GitHub]
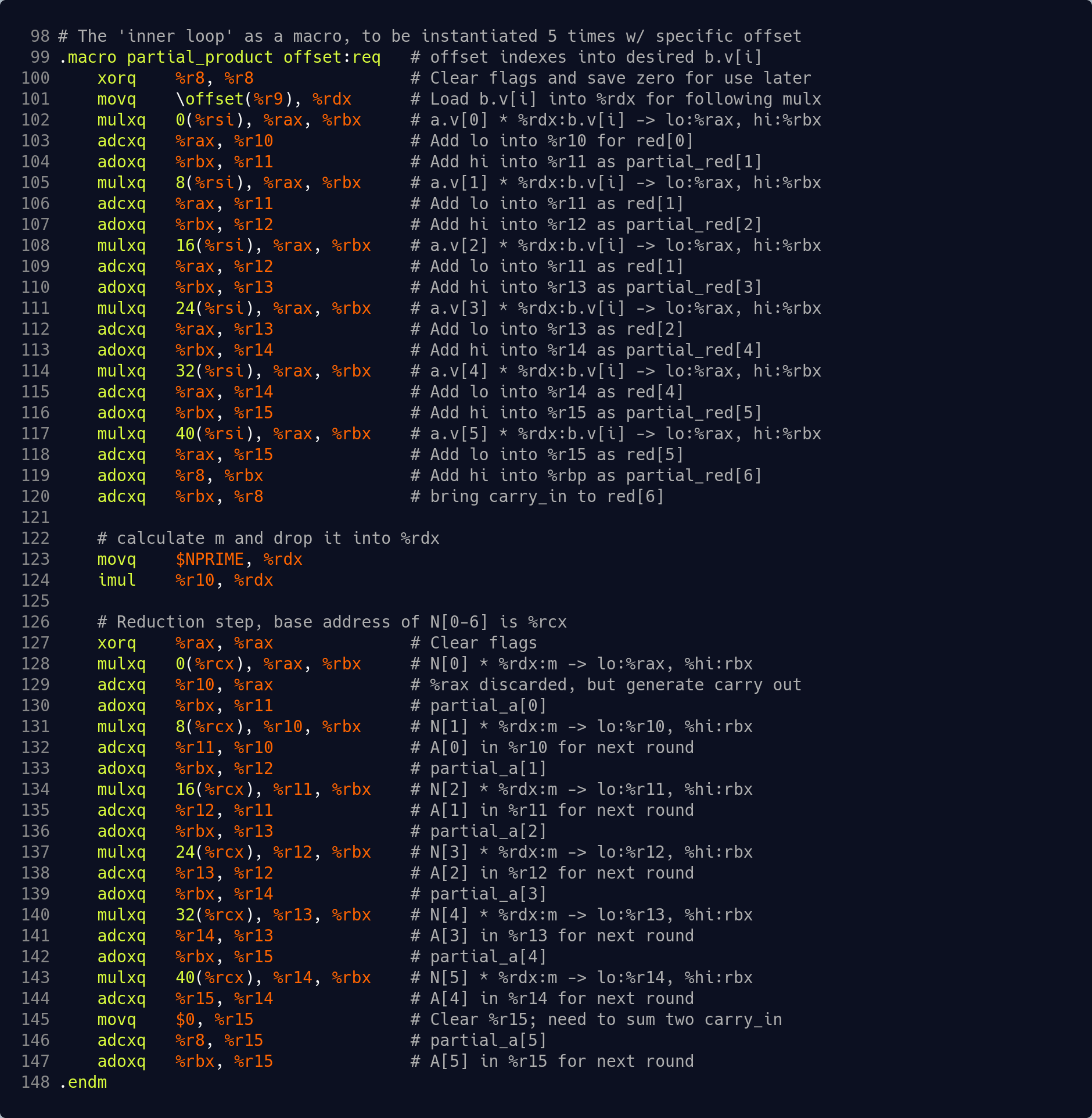
The final Montgomery multiplication function is fully implemented in src/mont_mul_asm.S and is a straightforward concatenation of the following elements:
- A function label attached to the prologue. Any registers used by the function that are required to be preserved across function calls must be pushed to the stack prior to use. The label corresponds to the extern “C” clause in the Rust lib.rs source file.
- The MODULUS is stored as quadword constants and their address loaded into the %rcx register. These values are utilized in the reduction step.
- An instance of the simplified first outer loop.
- Five instances of the macro shown above. Note the presence of offset parameter on line 82. This is used to form an index into b.v[i] on line 84 and it is increased by 8 on each instance.
- The final modulus correction logic is virtually identical to what has already been seen for addition: subtract the modulus from the initial result and return that if there is no borrow, otherwise return the initial result.
- A function epilogue that pops the registers from the stack that were pushed there in the prologue.
Again, the full routine can be seen in its totality here on GitHub. Note that the Rust build.rs source file integrates everything with cargo such that there are no additional steps required to build.
A final aside: Unrolling Rust and intrinsics
The code repository already fully supports further experimentation with A) flattened Rust code that uses the same strategy to minimize its active working set, and B) Rust intrinsics. Let’s briefly touch on both topics before including them in the benchmarking results described next.
The assembly code can be back-ported or re-implemented back into flat/raw Rust with the same ‘register allocation’ strategy to manage the active working set and avoid declaring a temp[] array. This gives surprisingly good results and suggests that a modern micro-architecture can look even further ahead, perhaps up to 200 (simple) instructions, to extract more instruction level parallelism from separate but adjacent carry chains. Hence the old adage: “You can rarely outsmart the compiler”. Look for the fe_mont_mul_raw() function.
Alternatively, Rust provides intrinsics that specifically target the ADCX, ADOX and MULX instructions. Unfortunately, the toolchain cannot emit the first two yet. Nonetheless, the fe_mont_mul_intrinsics() function shows exactly how this is coded. The MULX instruction is indeed emitted and does deliver a significant benefit by not interfering with the flags.
Benchmarking
Everything is ready to go – let’s benchmark! Here are sample results from my machine:
$ RUSTFLAGS="--emit asm -C target-cpu=native" cargo bench Ubuntu 20.04.2 LTS on Intel Core i7-7700K CPU @ 4.20GHz with Rust version 1.53 1. Addition X 1000 iterations [3.6837 us 3.6870 us 3.6905 us] 2. Subtraction X 1000 iterations [3.1241 us 3.1242 us 3.1244 us] 3. Multiplication by BigUint X 1000 iterations: [517.54 us 517.68 us 517.85 us] 4. Multiplication in Rust (mont1 blog) X 1000 iter: [46.037 us 46.049 us 46.064 us] 5. Multiplication in flat Rust X 1000 iterations: [34.719 us 34.741 us 34.763 us] 6. Multiplication in Rust with intrinsics X 1000 iter: [31.497 us 31.498 us 31.500 us] 7. Multiplication in Rust with assembly X 1000 iter: [29.573 us 29.576 us 29.580 us]
There are three caveats to consider while interpreting the above results. First and foremost, consider these results as a qualitative sample rather than a definitive result. Second, each result is presented as minimum, nominal and maximum timing – so the key figure is the central number. Finally, each function is timed across 1000 iterations, so the timing result for a single iteration correspond to units of nanoseconds rather than microseconds. On this machine, the Montgomery multiplication function written in assembly language takes approximately 29.576 ns.
The baseline non-Montgomery multiplication function utilizing BigUint is shown in entry 3. The (non BigUint) Montgomery multiplication function developed in the prior post is entry 4. The benefits of actively managing the working set and unrolling the inner loops can be seen in entry 5. The benefit of the MULX intrinsic appears in entry 6. Pure assembly is shown in entry 7. While the assembly routine provides more than 15X performance improvement over the BigUint reference implementation in entry 3, it also utilizes the CMOV instructions in the final correction steps to reduce timing side-channel leakage relative to all other entries.
What we learned
We started with a reference multiplication routine utilizing the BigUint library crate as our performance baseline. Then we adapted the Montgomery multiplication function in Rust from the prior blog post into an equivalent x86-64 assembly language version that is over 15X faster than the baseline. Along the way we looked at how the micro-architecture supports increased parallelism, how several new instructions in the architecture also support increased parallelism, and got insight into how to use the instructions with planned register allocations. A few hints (leading to intentionally unanswered questions) were dropped regarding the potential of raw Rust and intrinsics, with further investigation left as an exercise for the reader. Finally, we benchmarked a broad range of approaches.
The code is available publicly on GitHub, self-contained and ready for further experimentation.
What is next?
As mentioned at the start, pairing-based cryptography involves a wide range of algorithms, techniques and optimizations. This will provide a large menu of follow-on optimization topics which may ultimately include the polynomial-related functionality that zkSNARKS utilize with pairings. Stay tuned!!
Thank you
The author would like to thank Parnian Alimi, Paul Bottinelli and Thomas Pornin for detailed review and feedback. The author is solely responsible for all remaining issues.
