At Fox-IT (part of NCC Group) identifying servers that host nefarious activities is a critical aspect of our threat intelligence. One approach involves looking for anomalies in responses of HTTP servers.
Sometimes cybercriminals that host malicious servers employ tactics that involve mimicking the responses of legitimate software to evade detection. However, a common pitfall of these malicious actors are typos, which we use as unique fingerprints to identify such servers. For example, we have used a simple extraneous whitespace in HTTP responses as a fingerprint to identify servers that were hosting Cobalt Strike with high confidence1. In fact, we have created numerous fingerprints based on textual slipups in HTTP responses of malicious servers, highlighting how fingerprinting these servers can be a matter of a simple mistake.
HTTP servers are expected to follow the established RFC guidelines of HTTP, producing consistent HTTP responses in accordance with standardized protocols. HTTP responses that are not set up properly can have an impact on the safety and security of websites and web services. With these considerations in mind, we decided to research the possibility of identifying unknown malicious servers by proactively searching for textual errors in HTTP responses.
HTTP response headers and semantics
HTTP is a protocol that governs communication between web servers and clients2. Typically, a client, such as a web browser, sends a request to a server to achieve specific goals, such as requesting to view a webpage. The server receives and processes these requests, then sends back corresponding responses. The client subsequently interprets the message semantics of these responses, for example by rendering the HTML in an HTTP response (see example 1).

An HTTP response includes the status code and status line that provide information on how the server is responding, such as a ‘404 Page Not Found’ message. This status code is followed by response headers. Response headers are key:value pairs as described in the RFC that allow the server to give more information for context about the response and it can give information to the client on how to process the received data. Ensuring appropriate implementation of HTTP response headers plays a crucial role in preventing security vulnerabilities like Cross-Site Scripting, Clickjacking, Information disclosure, and many others3.

Methodology
The purpose of this research is to identify textual deviations in HTTP response headers and verify the servers behind them to detect new or unknown malicious servers. To accomplish this, we collected a large sample of HTTP responses and applied a spelling-checking model to flag any anomalous responses that contained deviations (see example 3 for an overview of the pipeline). These anomalous HTTP responses were further investigated to determine if they were originating from potentially malicious servers.
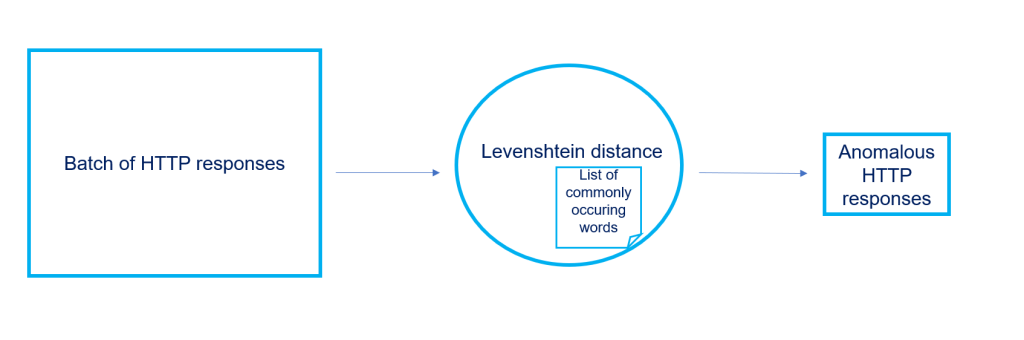
Data: Batch of HTTP responses
We sampled approximately 800,000 HTTP responses from public Censys scan data4. We also created a list of common HTTP response header fields, such as ‘Cache-Control’, ‘Expires’, ‘Content-Type’, and a list of typical server values, such as ‘Apache’, ‘Microsoft-IIS’, and ‘Nginx.’ We included a few common status codes like ‘200 OK,’ ensuring that the list contained commonly occurring words in HTTP responses to serve as our reference.
Metric: The Levenshtein distance
To measure typos, we used the Levenshtein distance, an intuitive spelling-checking model that measures the difference between two strings. The distance is calculated by counting the number of operations required to transform one string into the other. These operations can include insertions, deletions, and substitutions of characters. For example, when comparing the words ‘Cat’ and ‘Chat’ using the Levenshtein distance, we would observe that only one operation is needed to transform the word ‘Cat’ into ‘Chat’ (i.e., adding an ‘h’). Therefore, ‘Chat’ has a Levenshtein distance of one compared to ‘Cat’. However, comparing the words ‘Hats’ and ‘Cat’ would require two operations (i.e., changing ‘H’ to ‘C’ and adding an ‘s’ in the end), and therefore, ‘Hats’ would have a Levenshtein distance of two compared to ‘Cat.’
The Levenshtein distance can be made sensitive to capitalization and any character, allowing for the detection of unusual additional spaces or lowercase characters, for example. This measure can be useful for identifying small differences in text, such as those that may be introduced by typos or other anomalies in HTTP response headers. While HTTP header keys are case-insensitive by specification, our model has been adjusted to consider any character variation. Specifically, we have made the ‘Server’ header case-sensitive to catch all nuances of the server’s identity and possible anomalies.
Our model performs a comparative analysis between our predefined list (of commonly occurring HTTP response headers and server values) and the words in the HTTP responses. It is designed to return words that are nearly identical to those of the list but includes small deviations. For instance, it can detect slight deviations such as ‘Content-Tyle’ instead of the correct ‘Content-Type’.
Output: A list with anomalous HTTP responses
The model returned a list of two hundred anomalous HTTP responses from our batch of HTTP responses. We decided to check the frequency of these anomalies over the entire scan dataset, rather than the initial sample of 800.000 HTTP Responses. Our aim was to get more context regarding the prevalence of these spelling errors.
We found that some of these anomalies were relatively common among HTTP response headers. For example, we discovered more than eight thousand instances of the HTTP response header ‘Expired’ instead of ‘Expires.’ Additionally, we saw almost three thousand instances of server names that deviated from the typical naming convention of ‘Apache’ as can be seen in table 1.
| Deviation | Common name | Amount |
| Server: Apache Coyote | Server: Apache-Coyote | 2941 |
| Server: Apache \r\n | Server: Apache | 2952 |
| Server: Apache. | Server: Apache | 3047 |
| Server: CloudFlare | Server: Cloudflare | 6615 |
| Expired: | Expires: | 8260 |
Refining our research: Delving into the rarest anomalies
However, the rarest anomalies piqued our interest, as they could potentially indicate new or unknown malicious servers. We narrowed our investigation by only analyzing HTTP responses that appeared less than two hundred times in the wild and cross-referenced them with our own telemetry. By doing this, we could obtain more context from surrounding traffic to investigate potential nefarious activities. In the following section, we will focus on the most interesting typos that stood out and investigate them based on our telemetry.
Findings
Anomalous server values
During our investigation, we came across several HTTP responses that displayed deviations from the typical naming conventions of the values of the ‘Server’ header.
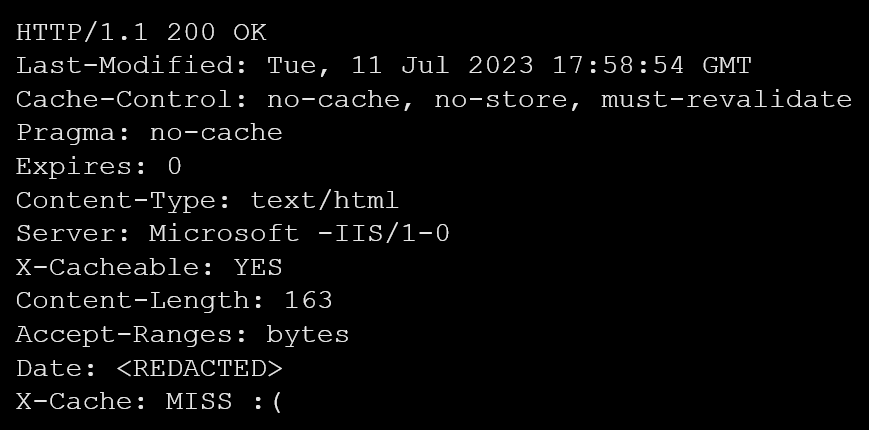
For instance, we encountered an HTTP response header where the ‘Server’ value was written differently than the typical ‘Microsoft-IIS’ servers. In this case, the header read ‘Microsoft -IIS’ instead of ‘Microsoft-IIS’ (again, note the space) as shown in example 3. We suspected that this deviation was an attempt to make it appear like a ‘Microsoft-IIS’ server response. However, our investigation revealed that a legitimate company was behind the server which did not immediately indicate any nefarious activity. Therefore, even though the typo in the server’s name was suspicious, it did not turn out to come from a malicious server.
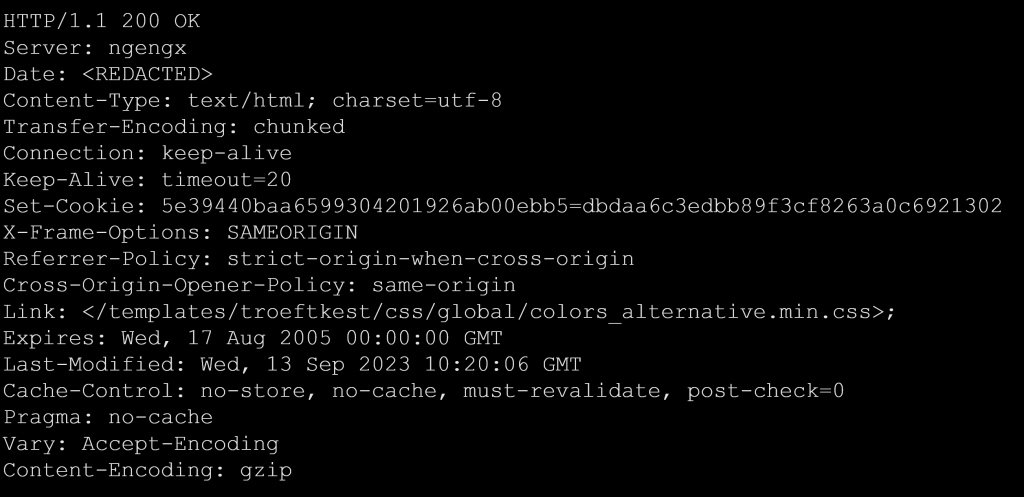
The ‘ngengx’ server value appeared to intentionally mimic the common server name ‘nginx’ (see example 4). We found that it was linked to a cable setup account from an individual that subscribed to a big telecom and hosting provider in The Netherlands. This deviation from typical naming conventions was strange, but we could not find anything suspicious in this case.
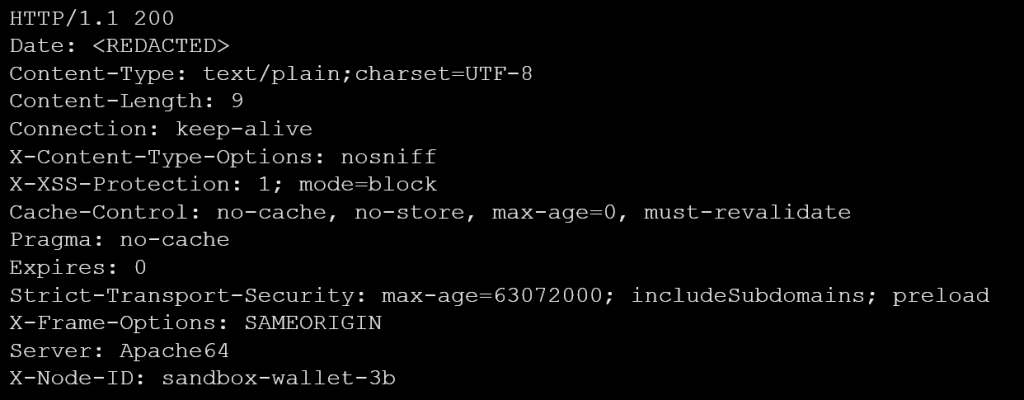
Similarly, the ‘Apache64’ server value deviates from the standard ‘Apache’ server value (see example 5). We found that this HTTP response was associated with webservers of a game developer, and no apparent malevolent activities were detected.
While these deviations from standard naming conventions could potentially indicate an attempt to disguise a malicious server, it does not always indicate nefarious activity.
Anomalous response headers
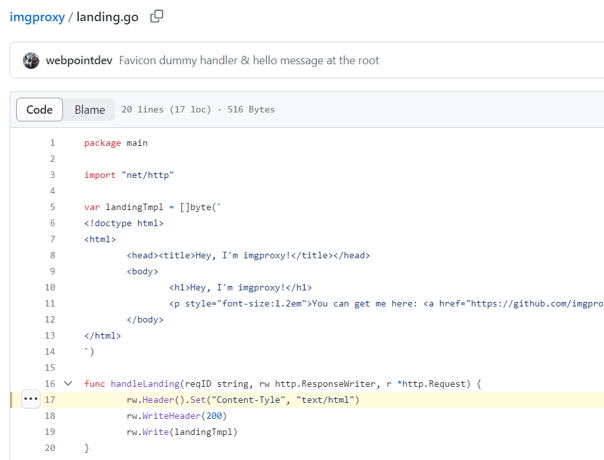
Moreover, we encountered HTTP response headers that deviated from the standard naming conventions. The ‘Content-Tyle’ header deviated from the standard ‘Content-Type’ header, and we found both the correct and incorrect spellings within the HTTP response (see example 6). We discovered that these responses originated from ‘imgproxy,’ a service designed for image resizing. This service appears to be legitimate. Moreover, a review of the source code confirms that the ‘Content-Tyle’ header is indeed hardcoded in the landing page source code (see Example 7).
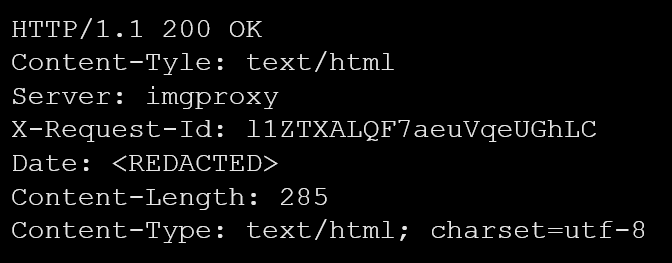
Similarly, the ‘CONTENT_LENGTH’ header deviated from the standard spelling of ‘Content-Length’ (see example 7). However, upon further investigation, we found that the server behind this response also belongs to a server associated with webservers of a game developer. Again, we did not detect any malicious activities associated with this deviation from typical naming conventions.
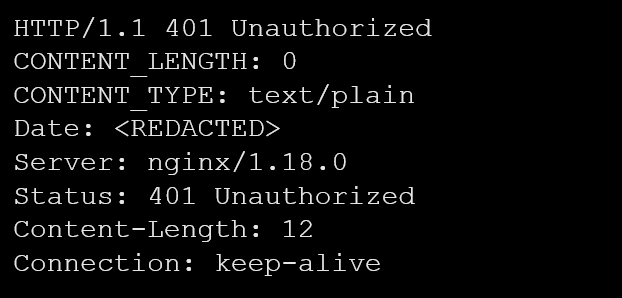
The findings of our research seem to reveal that even HTTP responses set up by legitimate companies include messy and incorrect response headers.
Concluding Insights
Our study was designed to uncover potentially malicious servers by proactively searching for spelling mistakes in HTTP response headers. HTTP servers are generally expected to adhere to the established RFC guidelines, producing consistent HTTP responses as dictated by the standard protocols. Sometimes cybercriminals hosting malicious servers attempt to evade detection by imitating standard responses of legitimate software. However, sometimes they slip up, leaving inadvertent typos, which can be used for fingerprinting purposes.
Our study reveals that typos in HTTP responses are not as rare as one might assume. Despite the crucial role that appropriate implementation of HTTP response headers plays in the security and safety of websites and web services, our research suggests that textual errors in HTTP responses are surprisingly widespread, even in the outputs of servers from legitimate organizations. Although these deviations from standard naming conventions could potentially indicate an attempt to disguise a malicious server, they do not always signify nefarious activity. The internet is simply too messy.
Our research concludes that typos alone are insufficient to identify malicious servers. Nevertheless, they retain potential as part of a broader detection framework. We propose advancing this research by combining the presence of typos with additional metrics. One approach involves establishing a baseline of common anomalous HTTP responses, and then flagging HTTP responses with new typos as they emerge.
Furthermore, more research could be conducted regarding the order of HTTP headers. If the header order in the output differs from what is expected from a particular software, in combination with (new) typos, it may signal an attempt to mimic that software.
Lastly, this strategy could be integrated with other modelling approaches, such as data science models in Security Operations Centers. For instance, monitoring servers that are not only new to the network but also exhibit spelling errors. By integrating these efforts, we strive to enhance our ability to detect emerging malicious servers.
References
- Fox-IT (part of NCC Group). “Identifying Cobalt Strike Team Servers in the Wild”: https://blog.fox-it.com/2019/02/26/identifying-cobalt-strike-team-servers-in-the-wild/ ↩︎
- RFC 7231: https://www.rfc-editor.org/rfc/rfc7231 ↩︎
- OWASP: https://cheatsheetseries.owasp.org/cheatsheets/HTTP_Headers_Cheat_Sheet.html
https://owasp.org/www-project-secure-headers/ ↩︎ - Censys: https://search.censys.io/ ↩︎
